📌 정규화(Normalization)란?
관계형 데이터베이스에서 중복을 최소화하고 이상현상(삽입이상, 갱신이상, 삭제이상)을 없애는 것
📌 1차 정규화
테이블의 컬럼이 원자값을 가지도록 하는 것
<정규화 전>
| 이름 | 취미 |
| 한소희 | 독서, 쇼핑 |
| 천우희 | 노래, 춤 |
| 전여빈 | 게임 |
현재 한소희와 천우희의 취미를 보면 원자값이 아닌 다중값으로 들어가있기 때문에 1차 정규형을 만족하지 못한다.
따라서 1차 정규화를 진행한다.
<정규화 후>
| 이름 | 취미 |
| 한소희 | 독서 |
| 한소희 | 쇼핑 |
| 천우희 | 노래 |
| 천우희 | 춤 |
| 전여빈 | 게임 |
📌 2차 정규화
1차 정규화를 한 테이블이 완전 함수 종속을 만족하도록(= 부분 함수 종속이 없도록) 테이블을 분해하는 것
즉, 후보키가 복합키(다중칼럼)로 설정되어 있을 때 복합키의 일부칼럼에 다른칼럼들이 결정되어서는 안된다.
완전 함수적 종속과 부분 함수적 종속을 그림으로 나타내면 다음과 같다.
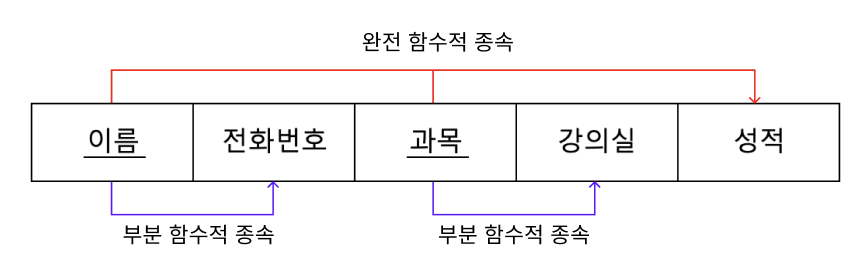
* 제1정규형 테이블의 기본키가 복합키가 아닌 단일키이면 자동으로 제2정규형을 만족한다.
테이블로 더 자세히 알아보자
<정규화 전>
| 이름 | 전화번호 | 과목 | 강의실 | 성적 |
| 한소희 | 010-1234-5678 | 데이터베이스 | 101 | A+ |
| 이지은 | 010-2345-6789 | 운영체제 | 202 | A0 |
| 한소희 | 010-1234-5678 | 파이썬 | 303 | B+ |
| 천우희 | 010-3456-7890 | 데이터베이스 | 101 | A0 |
현재 테이블에서 기본키를 (이름, 과목)으로 했을 때, 이 기본키는 전화번호, 강의실, 성적을 결정한다.
이 테이블은 위의 그림과 같이 완전 함수적 종속과 부분 함수적 종속이 모두 존재한다.
성적 -> 완전 함수적 종속
- 이름만 봤을 때 결정되지 않음 (한소희라는 이름을 가지는 성적값은 A+, B+ 두 개)
- 과목만 봤을 때 결정되지 않음 (데이터베이스 과목의 성적 값은 A+, A0 두 개)
전화번호, 강의실 -> 부분 함수적 종속
- 이름만 봤을 때 전화번호가 결정됨 (과목을 볼 필요 없음)
- 과목만 봤을 때 강의실이 결정됨 (전화번호를 볼 필요 없음)
따라서 부분 함수적 종속을 없애기 위한 제2 정규화가 필요하다.
<정규화 후>
이름, 과목 -> 성적
| 이름 | 과목 | 성적 |
| 한소희 | 데이터베이스 | A+ |
| 이지은 | 운영체제 | A0 |
| 한소희 | 파이썬 | B+ |
| 천우희 | 데이터베이스 | A0 |
이름 -> 전화번호
| 이름 | 전화번호 |
| 한소희 | 010-1234-5678 |
| 이지은 | 010-2345-6789 |
| 천우희 | 010-3456-7890 |
과목 -> 강의실
| 과목 | 강의실 |
| 데이터베이스 | 101 |
| 운영체제 | 202 |
| 파이썬 | 303 |
📌 3차 정규화
제 2정규형을 만족하는 테이블에 대해 이행 함수 종속이 없는 것
이행 함수 종속은 A -> B, B -> C가 성립할 때 A -> C가 성립 되는 것을 말한다.
이행 함수 종속을 그림으로 나타내면 다음과 같다.
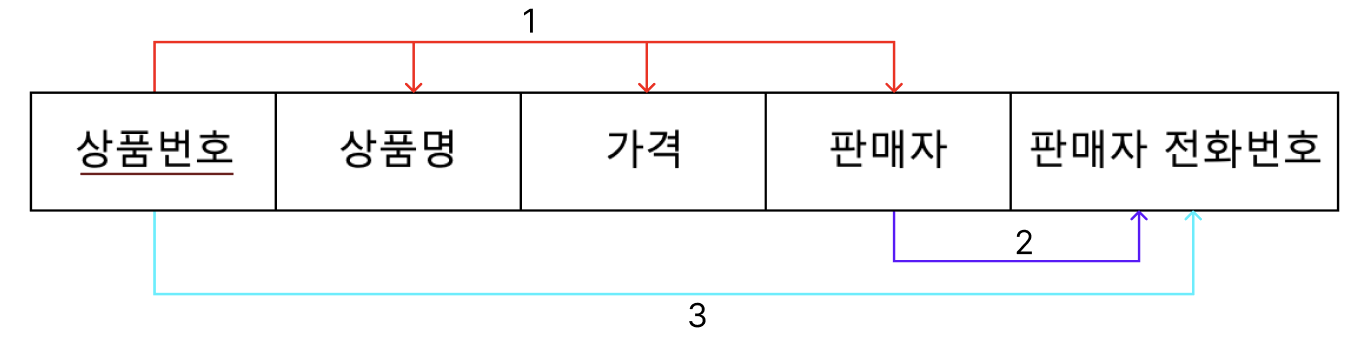
상품번호가 기본키라고 했을 때 상품번호는 상품명, 가격, 판매자, 판매자 전화번호를 결정한다.
여기서 이행 함수 종속을 따져보면, 판매자는 판매자 전화번호를 결정한다.
따라서 상품번호 -> 판매자 -> 판매자 전화번호이기 때문에
판매자 -> 판매자 전화번호를 결정한다.
<정규화 전>
| 상품번호 | 상품명 | 가격 | 판매자 | 판매자 전화번호 |
| 1111 | 아이폰 14 | 600000 | 한소희 | 010-1234-5678 |
| 2222 | LG 그램 | 1000000 | 이지은 | 010-2345-6789 |
| 3333 | 아이폰 14 pro | 800000 | 한소희 | 010-1234-5678 |
이 테이블에서 상품번호에 따라 상품명, 가격, 판매자, 판매자 전화번호가 결정되지만,
판매자에 따라 판매자 전화번호도 결정된다.
이행 함수 종속을 삭제하기 위한 3차 정규화를 쉽게 하기 위해

이렇게 나눠주면 된다.
<정규화 후>
| 상품번호 | 상품명 | 가격 | 판매자 |
| 1111 | 아이폰 14 | 600000 | 한소희 |
| 2222 | LG 그램 | 1000000 | 이지은 |
| 3333 | 아이폰 14 pro | 800000 | 한소희 |
| 판매자 | 판매자 전화번호 |
| 한소희 | 010-1234-5678 |
| 이지은 | 010-2345-6789 |
📌 보이스코드 정규화
3차 정규화를 진행한 테이블에 대해 모든 결정자가 후보키가 되도록 테이블을 분해하는 것
즉, 식별자로 쓰이는 속성이 일반 속성에 종속되지 않아야 한다.
식별자로 쓰이는 속성이 일반 속성에 종속되는 것을 그림으로 나타내면 다음과 같다.
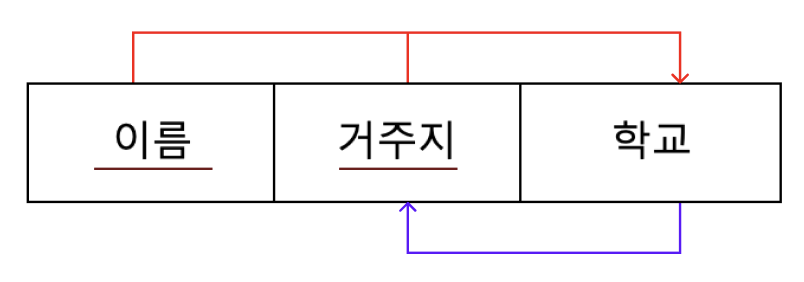
기본키를 (이름, 거주지)로 설정했을 때 기본키는 학교를 결정한다.
하지만 학교는 다시 거주지를 결정할 수 있을 때 보이스코드 정규화가 필요하다.
2차 정규화와 비슷해 보일 수 있는데,
2차 정규화는 복합키의 일부가 일반 속성을 결정하는 것이다.
보이스 코드 정규화를 테이블로 보면 다음과 같다.
<정규화 전>
| 이름 | 거주지 | 학교 |
| 고윤정 | 강남 | 서울여자대학교 |
| 김태희 | 강서 | 서울대학교 |
| 권정열 | 강남 | 연세대학교 |
| 한지민 | 강남 | 서울여자대학교 |
(이름, 거주지)는 학교를 결정한다.
하지만 학교도 거주지를 결정할 수 있다.
<정규화 후>
| 이름 | 거주지 |
| 고윤정 | 강남 |
| 김태희 | 강서 |
| 권정열 | 강남 |
| 한지민 | 강남 |
| 학교 | 거주지 |
| 서울여자대학교 | 강남 |
| 서울대학교 | 강서 |
| 연세대학교 | 강남 |
📌 참고
https://jhnyang.tistory.com/360