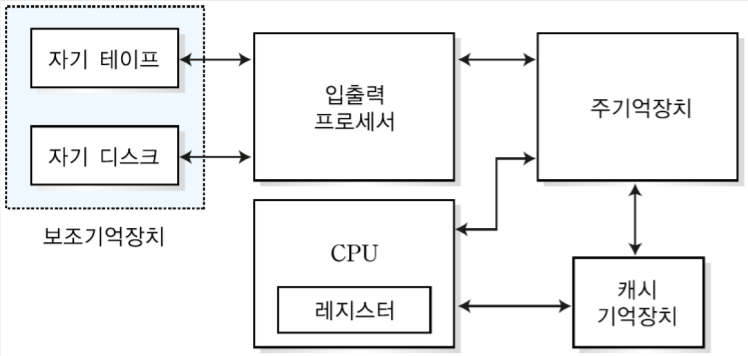
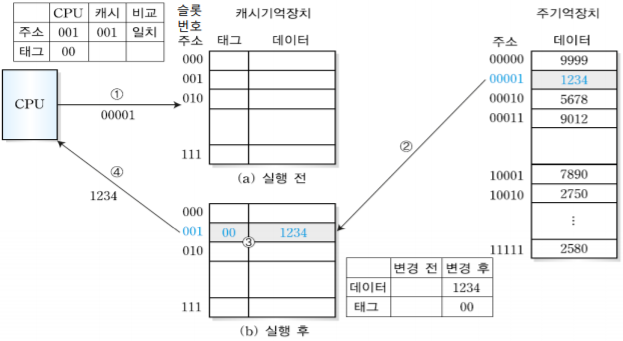
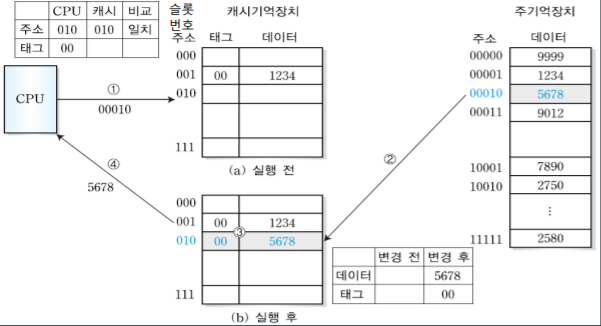
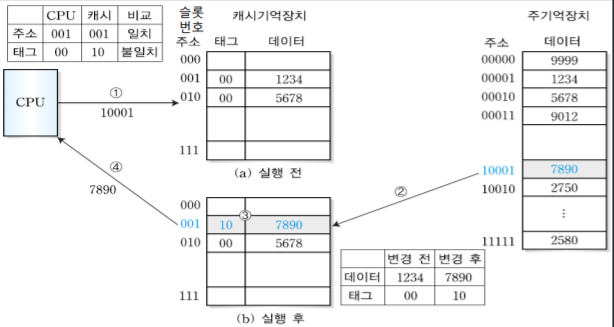
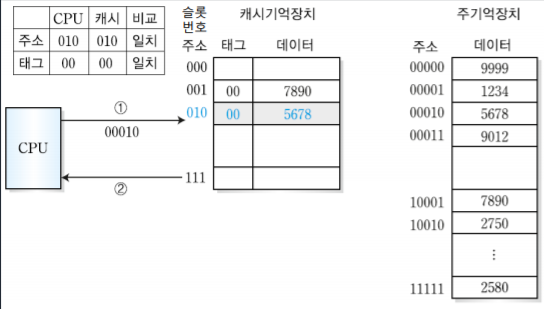
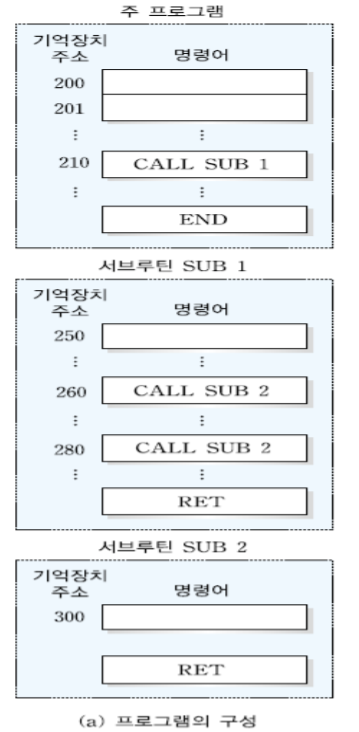
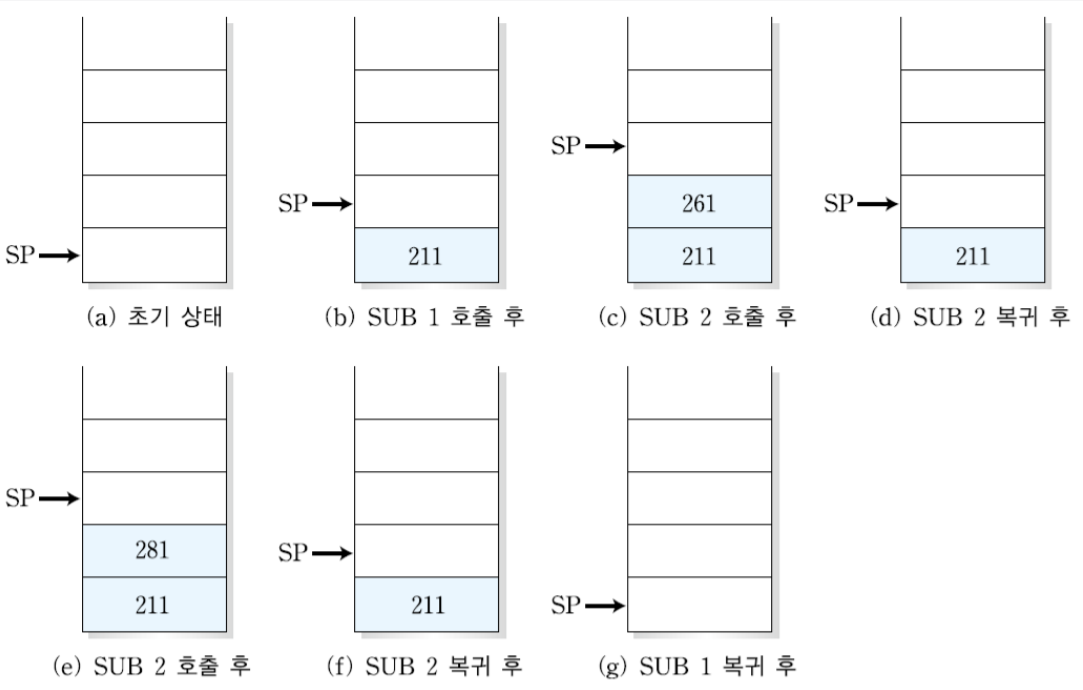
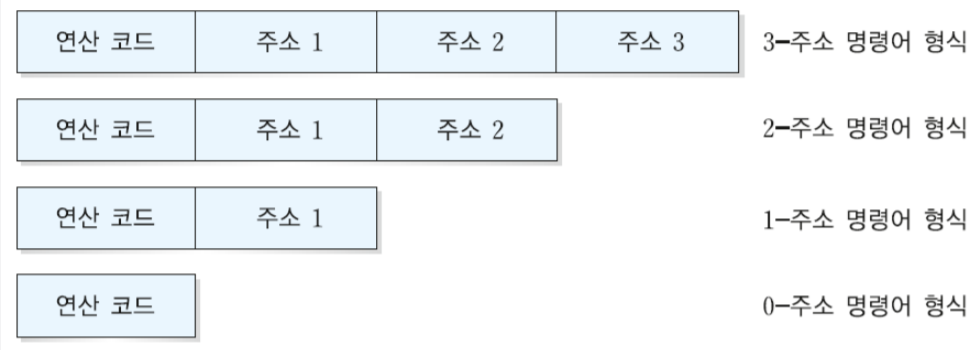
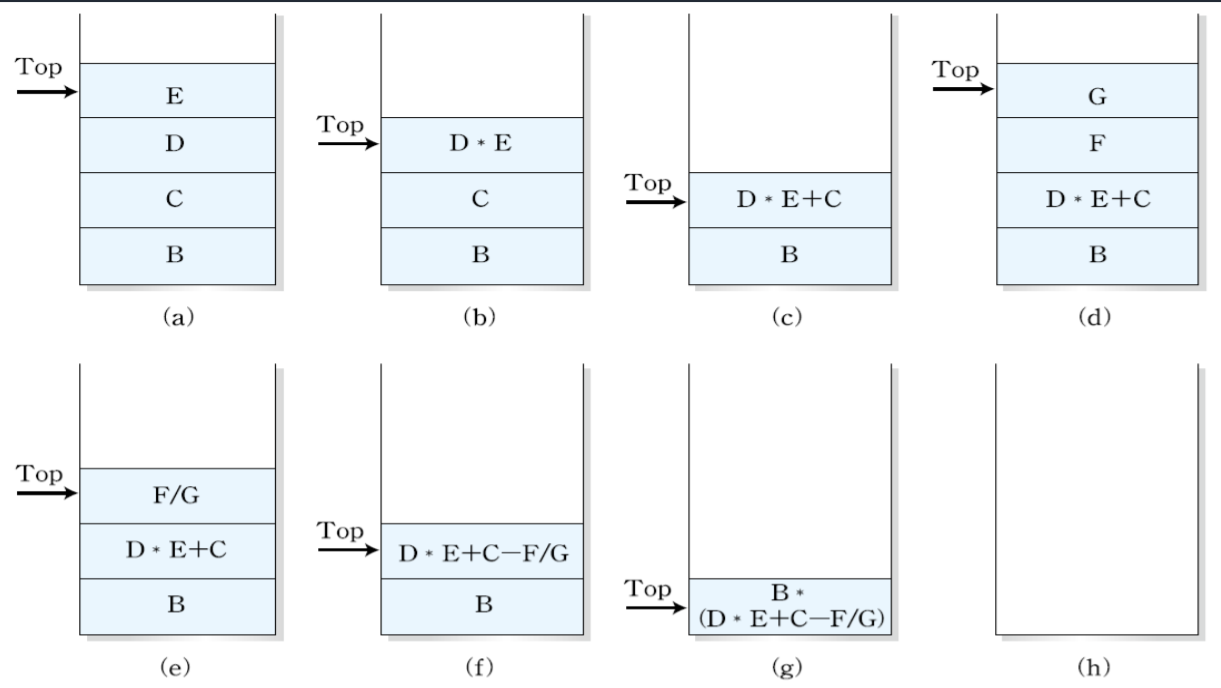
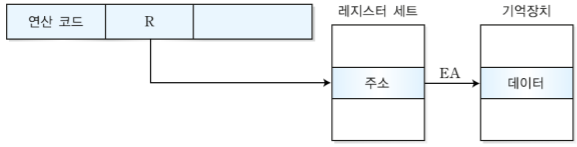
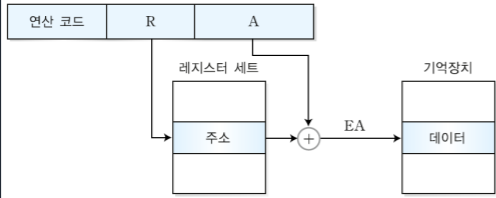
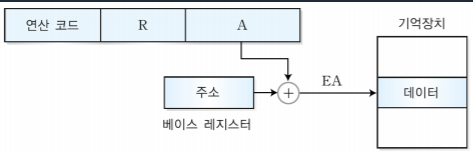
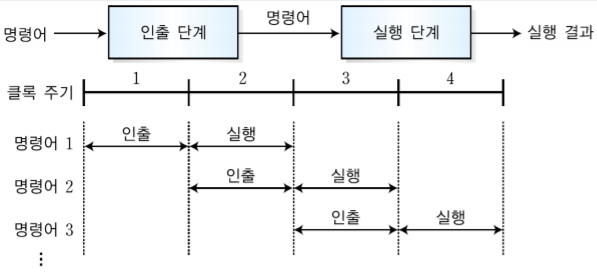
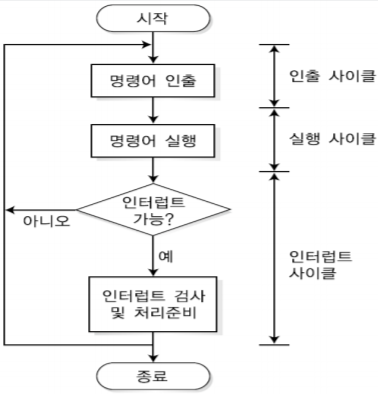
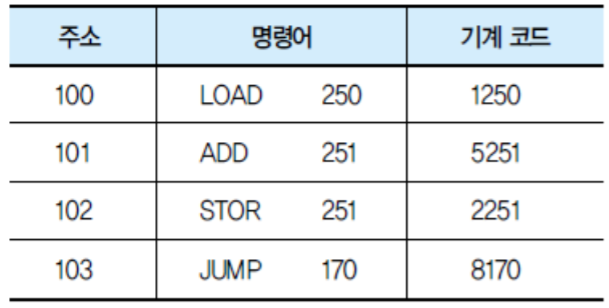
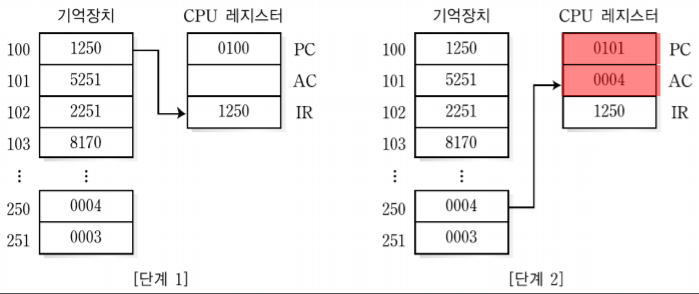
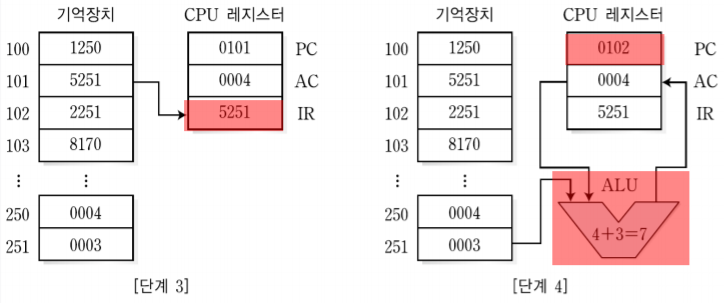
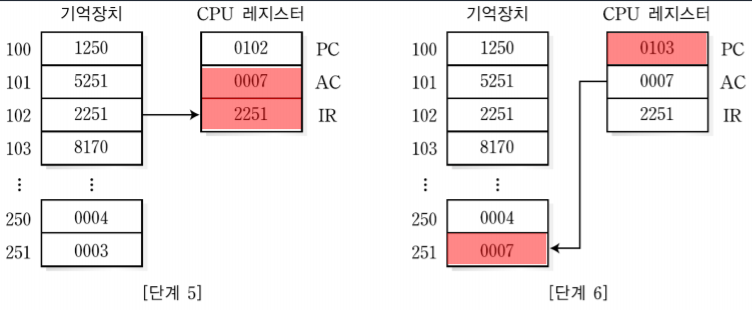
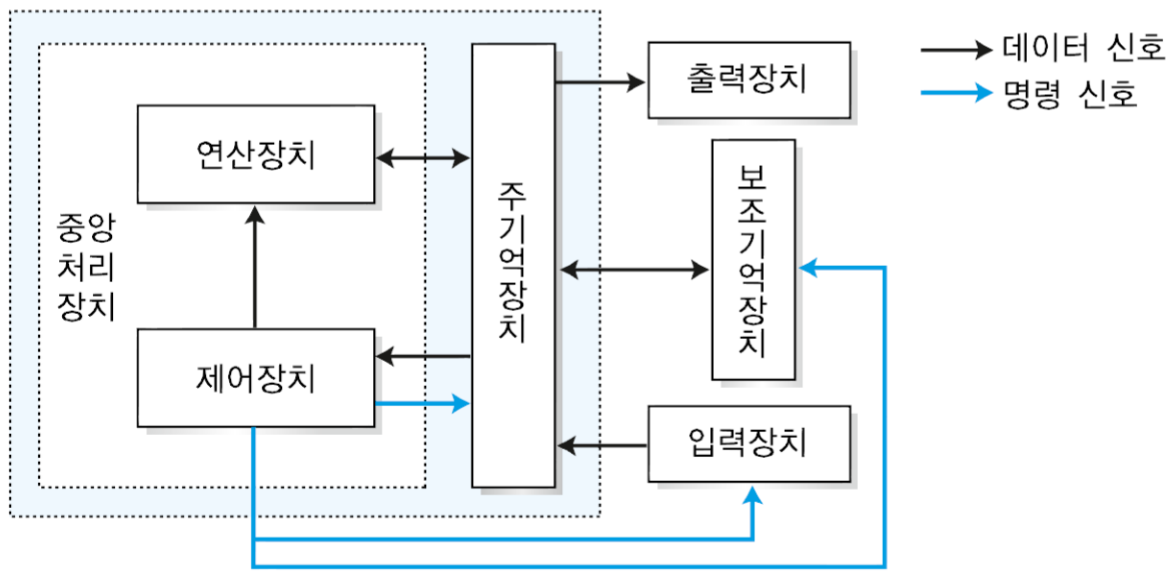
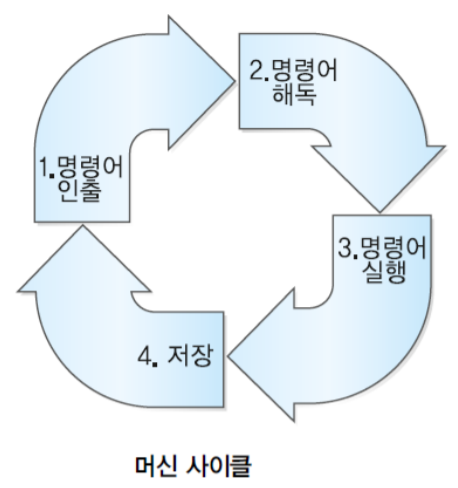
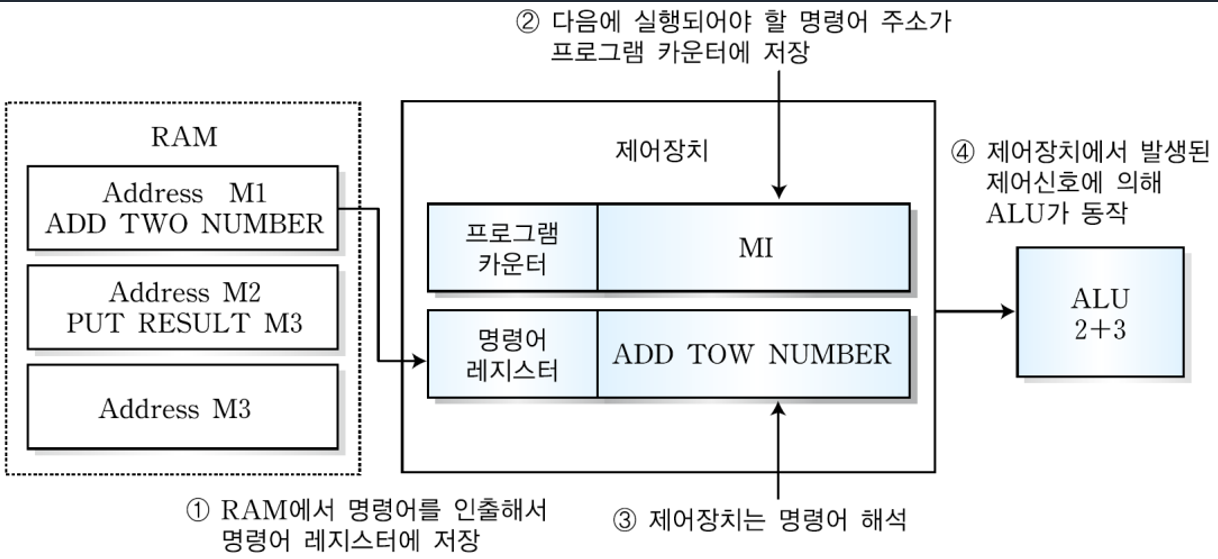
1. MIPS 시스템의 개요
-MIPS는 S(Microprocessor without interlocked pipeline stage의 약자로 컴퓨터 분야에서 밉스 테크놀로지에서 개발한 축소 명령 집합 컴퓨터(RISC)의 구조 및 그 구조를 이용한 마이크로프로세서임.
-1980년대 스탠포드대학에서 John Hennessy와 그의 동료들에 의해 개발됨
-Silicon Graphics, Nintendo, Cisco의 제품에서 사용되고 있음
2. 디자인 원리
-규칙적인 것이 간단성을 위해 좋음
-많이 발생되는 사항을 빨리 처리함
-적을수록 빠름
-좋은 설계는 좋은 절충안을 요구함
3. 설계 원칙 1
규칙적인 것이 간단성을 위해 좋음
-일관성있는 명령어 형태
-같은 수의 피연산자 (두 개의 source와 한 개의 destination)
-하드웨어로 구현하기 쉬움
명령어는 Addition(덧셈)과 Subtraction(뺄셈)뿐이다.
-Addition(덧셈)
a = b + c 는 밉스 어셈블리 코드로 add a, b, c 로 나타낼 수 있다. 여기서 add는 연산코드이며, a는 목적지, b와 c는 각각 소스1, 2이다. 밉스 어셈블리 코드에서는 무조건 destination코드 위치가 정해져있음을 주의한다.
-Subtraction(뺄셈)
a = b - c 는 밉스 어셈블리 코드로 sub a, b, c 로 나타낼 수 있다. 덧셈과 같이 sub는 연산코드, a는 목적지, b와 c는 각각 소스1, 소스2이다.
4. 설계 원칙 2
많이 발생되는 사항을 빨리 처리함
-MIPS: 단순하고, 많이 사용되는 명령어를 포함
-명령어를 해석하고 실행하는 하드웨어: 단순하고 빠름
-복잡한 명령어는 여러개의 단순한 명령어로 수행됨
명령어 한 줄을 처리하는 데 시간이 단축되어 빠르다는 장점이 있다.
컴퓨터 구조 분류
RISC (Reduced Instruction Set Computer): MIPS
CISC (Complex Set Instruction Set Computer): Intel의 IA-32
복잡한 코드: 여러개의 MIPS 명령어에 의해 처리됨
a = b + c - d 는 add t, b, c 와 sub a, t, d 라는 두 개의 밉스 명령어를 사용한다.
먼저 add t, b, c 는 t = b + c 라는 의미이며 sub a, t, c는 앞서 나온 결과 값 t를 이용하여 a = t - d 라는 의미이다. 즉 t 대신 b + c 를 넣으면 a = b + c - d 이기 때문에 같다.
5. 설계 원칙 3
적을수록 빠름
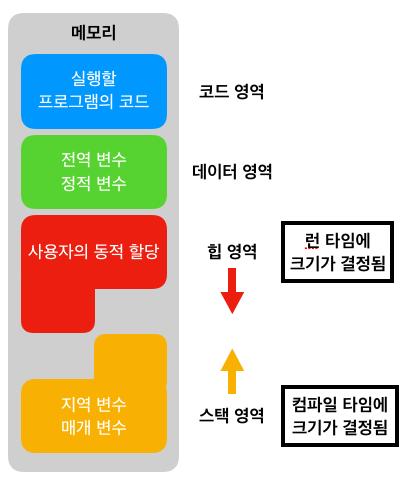
-MIPS: 적은수의 레지스터를 포함
-32개의 레지스터 (32 비트 또는 64 비트)
-32개의 레지스터로 부터 데이터를 획득하는 것이 1000개의 레지스터 또는 메모리로 부터 데이터를 획득하는 것 보다 빠름
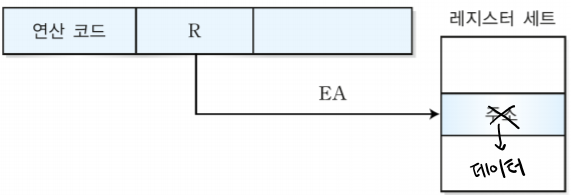
6. MIPS 레지스터 세트(레지스터 이름 / 레지스터 번호 / 사용법)
$0 / 0 / 상수값 0
$at / 1 / 어셈블러 임시용
$v0 - $v1 / 2 - 3 / 프로시저 리턴 값(함수 결과값)
$a0 - $a3 / 4 - 7 / 프로시저 인자
&t0 - $t7 / 8 - 15 / 임시 변수
$s0 - $s7 / 16 - 23 / 저장 변수
$t8 - $t9 / 24 - 25 / 임시 변수
$k0 - $k1 / 26 - 27 / 운영체제 임시용
$gp / 28 / 전역 포인터
$sp / 29 / 스택 포인터
$fp / 30 / 프레임 포인터
$ra / 31 / 프로시저 반환 주소
레지스터 마다 각각 할 일(역할)이 정해져있다.
7. 레지스터를 사용한 명령어
a = b + c 는 $s0 = a, $s1 = b, $s2 = c 일 때, add $s0, $s1, $s2 한 것과 같다.
a = b + c - d 는 $s0 = a, $s1 = b, $s2 = c, $s3 = d 일 때, sub $t0, $s2, $s3 와 add $s0, $s1, $t0 를 한 것과 같다.
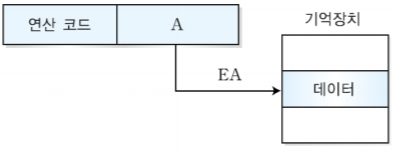
8. 워드(word) 주소 메모리
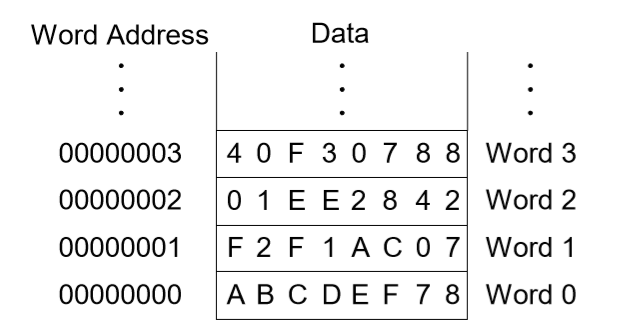
-load 명령어 (lw)
어셈블리 코드 lw $s3, 1($0) : ($0)은 상수값 0으로 1 + 0 = 1이며 워드 주소 1을 $s3에가져오라는 것이다. 즉 $s3이 목적지가 된다.
-store 명령어 (sw)
어셈블리 코드 sw $t4, 0x3($0) : ($0)은 상수값 0이므로 16진수의 3과 0을 더해 3이다. 여기서는 $t4가 source, 0x3($0)이 목적지이기 때문에 워드주소 3에 $t4의 값을 쓰라는 것이다.
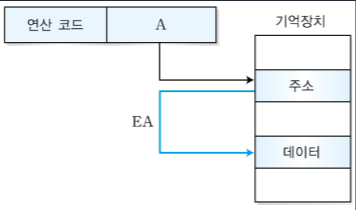
9. 바이트(byte) 주소 메모리
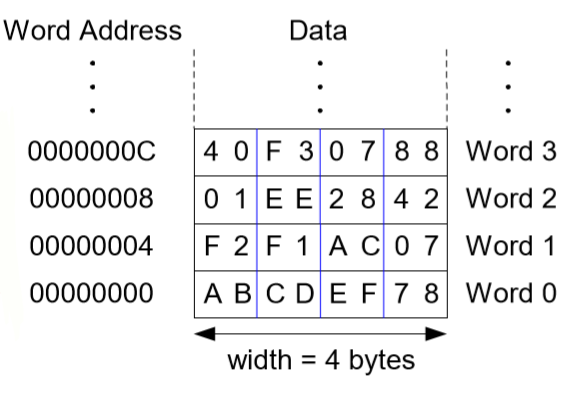
-load 명령어 (lw)
항상 가져오는 양은 1word로 정해져있다.
어셈블리 코드 lw $s3, 4($0) : ($0)은 상수값 0으로 4 + 0 = 4이다. 이는 워드 주소 4를 $s3으로 가져오라는 것이다. 즉 $s3이 목적지가 된다.
-store 명령어 (sw)
어셈블리 코드 sw $t7, 12($0) : ($0)은 상수값 0이므로 12와 0을 더해 12이다. 1여기서는 $t7이 source, 12($0)가 목적지이다. 즉 16진수로 12는 C이기 때문에 워드주소 C에 $t7의 값을 쓰라는 것이다.
10. 빅-엔디안, 리틀-엔디안
이는 데이터를 읽어오는 방식에 대해 차이가 있다.
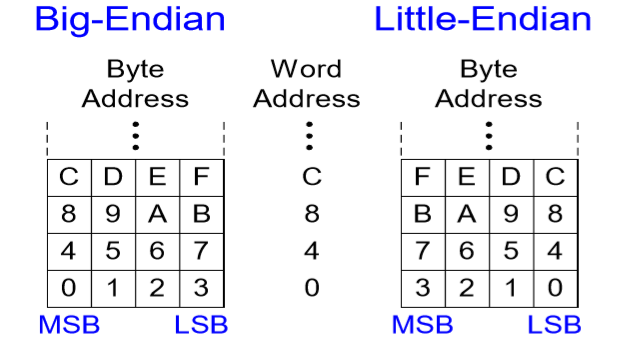
MSB는 제일 높은 주소, LSB는 제일 낮은 주소이다.
빅-엔디안은 높은 주소 -> 낮은 주소 순으로,
리틀-엔디안은 낮은 주소 -> 높은 주소 순으로 데이터를 읽어온다.
예제) $t0의 값이 0x23456789라고가정한다. 아래의프로그램이 Big-Endian 시스템과Little-Endian시스템에서 수행한 후에 $s0의값은?

sw $t0, 0($0)
lb $s0, 1($0) # 1+0 = 1 즉 1번지의 데이터 값을 $s0에 가져와라.
결과 값
Big-Endian: $s0 = 0x00000045
Little-Endian: $s0 = 0x00000067
해설
Big-Endian은 MSB -> LSB 순으로 데이터를 불러오기 때문에 45가 1번지이고,
Little-Endian은 LSB -> MSB 순으로 데이터를 불러오기 때문에 67가 1번지이다.
11. 설계 원칙 4
좋은 설계는 좋은 절충안을 요구함
-다중 명령어 형태는 융통성 제공
(1) add, sub: 3개의 레지스터 피연산자 사용
(2) lw, sw: 2개의 레지스터 피연산자와 상수 사용
:적은 수의 명령어 형태를 유지함
12. 기계어
기계어는 32비트 명령어로, 명령어들을 이진 표현한다. 즉 0과 1로만 나타낸다.
명령어 형태로 R-Type, I-Type, J-Type이 있다.
12-1. R-Type

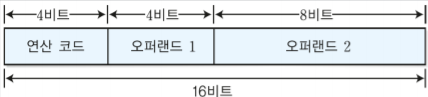
레지스터의 R을 사용한 R-Type은 3개의 레지스터 피연산자(오퍼랜드)를 갖는다.
rs, rt는 source 레지스터이며, rd는 destination 레지스터이다.
다른 필드는 op 즉 operation 코드(op코드), funct(function), shamt(shift 명령어에서 사용되는 shift 양)이 있다.
R-Type명령어에서는 op코드 값이 모두 0으로 무슨 타입인지 모를 때도 op값을 보고 알 수 있다.
shamt는 예로 곱셈, 나눗셈에서 사용되며, funct는 op가 모두 0이기 때문에 명령어를 분류하기 위해 사용한다.
예시)

어셈블리 코드를 먼저 10진수의 R-Type으로 바꾸면
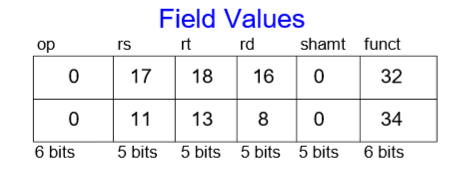
이렇게 된다. R-Type이기 때문에 op코드가 0, rs와 rt는 source, rd는 destination이다. 여기서는 곱셈과 나눗셈이 없으므로 둘 다 0이고 funct는 add는 32, sub은 34로 나타낸다.
이를 기계어 즉 2진수로 바꾸면
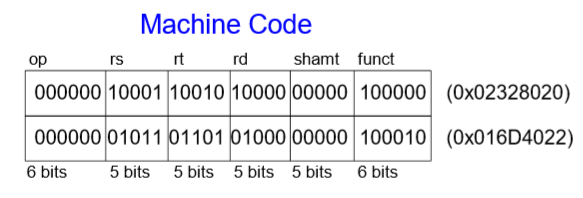
결론적으로 이런 값을 얻는다.
12-2. I-Type

즉시값(Immediate) 타입으로 3개의 피연산자(오퍼랜드)를 가진다. rs, rt는 레지스터 피연산자이며 imm은 16비트의 즉시값이다.
다른 필드로는 op코드가 있다.
R-Type과는 달리 funct가 존재하지 않는 이유는 op코드가 이미 개별적인 값을 갖기 때문이다.
여기서 중요한 점은 imm이 10진수의 상수값을 가지는 것이다.
예시)


addi에서 i는 즉시값 타입을 나타내고 있다. 여기서 rt가 목적지, rs와 imm이 source이다.
이를 I-Type으로 나타내면
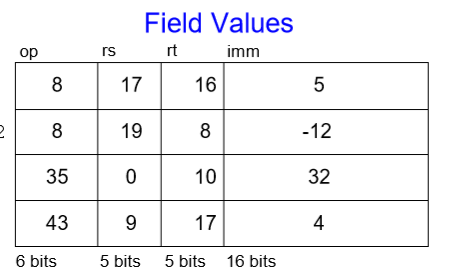
addi $s0, $s1, 5에서 $s0은 rt로, $s1은 rs로 상수 5는 imm값으로 들어간다. 또한 더하는 명령어의 op코드 값인 8이 op자리에 들어간다.
lw $t2, 32($0)에서 처럼 피연산자가 하나, imm값이 하나인 경우에는 피연산자가 rt값에 들어간다.
이를 기계어 코드로 바꾸면

결론적으로 이런 값을 얻는다.
12-3. J-Type
Jump타입으로 1개의 피연산자(오퍼랜드) addr를 가진다. 이는 주소 피연산자이다.
다른 필드로는 op코드가 있다.
분기 명령어 때 사용되는 명령어 형식이다.

addr은 어디로 갈 지의 데이터가 들어있다.
13. 기계어 코드 해석
순서
(1) opcode 분석
(2) opcode가 0이면 R-Type으로 funct비트를 통해서 명령어 기능 분석
(3) opcode가 0이 아니면, I-Type 또는 J-type 명령어
예시)
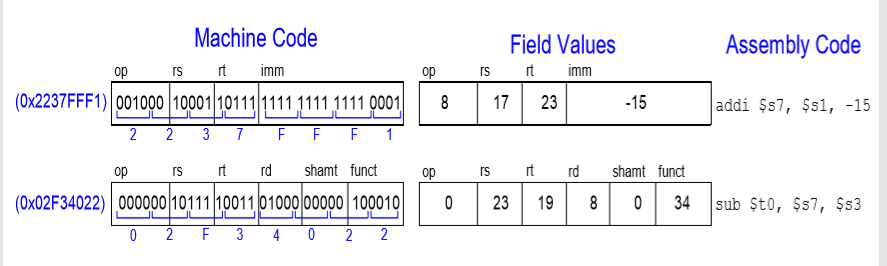
먼저 0x2237FFF1은 기계어 코드를 4비트씩 쪼개 16진수로 만든 것이다. 또한 op코드가 0이 아니고 imm이 있는 것을 보면 I-Type인 것을 알 수 있다.
0x02F34022도 기계어 코드를 4비트씩 쪼개 16진수로 만든 것이며 op코드가 0이므로 R-Type인 것을 알 수 있다.
14. 조건부 분기 (beq)

먼저 i가 붙은 것을 봐서 I-Type이다. 또한 첫 번째가 목적지임을 생각하고 코드를 분석하면
$s0 = 0 + 4 = 4
$s1 = 0 + 1 = 1
$s1 = 1 << 2 = 4 이다.
여기서 sll 은 시프트 연산으로 예를들어 0001을 왼쪽으로 2 시프트 하면 0100이 되기에 4가 된다.
이후 나오는 beq에서는 $s0과 $s1이 같으면 target으로 가라는 명령어다. 현재 $s0과 $s1은 4로 같기 때문에 target으로 바로 분기한다. 따라서 beq후에 나오는 addi와 sub명령어는 수행하지 않는다.
target에서의 코드는 $s1 = 4 + 4 = 8 이다.
15. 조건부 분기 (bne)

bne는 $s0과 $s1이 같지 않을 경우 분기하는데 여기서는 같기 때문에 분기 하지 않고 다음 명령어를 수행한다.
16. 무조건 분기 (j)

무조건 분기의 경우 조건을 따지지않고 분기하기 때문에 목적지 target만 있다.
j를 만나면 바로 분기한다. 따라서 sra, addi, sub의 명령어를 수행하지 않는다.
17. 무조건 분기 (jr)

jr은 레지스터를 가지는데 그 레지스터의 데이터를 주소로 판단한다.
즉 $s0으로 무조건 분기하라는 것으로 현재 $s0은 0x2010으로 lw명령어 주소이기 때문에 그곳으로 분기한다.
따라서 사이에 있는 addi와 sra명령어를 수행하지 않는다.
18. if문

if문의 조건은 i와 j가 같으면인데 mips에서는 bne 즉 i와 j가 같지 않으면을 쓴다.
그 이유는 if조건이 같지 않으면 수행을 하지 않아야 하기 때문이다.
bne에서 조건이 같지 않으면 add를 수행하면 안되기 때문에 L1으로 분기하는 것이다.
19. if/else문

그냥 if문과는 달리 j done이 추가된 것을 볼 수 있다.
if문의 조건이 아니면 else문을 실행해야 하기 때문에 mips에서 bne(조건이 다르면) L1으로 분기하라는 것이 있으며 마만약 조건이 같으면 분기 하지 않고 add를 수행한다. 이후 else문은 수행을 하면 안되므로 j를 사용해 done으로 무조건 분기한다.
20. while루프

while문에서 pow가 128이 아닐동안 수행하는 것이기 때문에 128이 되면 while문을 돌면 안된다. 따라서 mips에서 while문이 beq인 이유가 pow가 128이면 돌지 않고 분기해야하기 때문이다. 또한 while문의 마지막에 j가 있는 이유는 계속해서 돌아야하기 때문에 while로 다시 분기를 하는 것이다.
21. for루프

for문에서 i가 10이 아닐 동안 돌아야하기 때문에 i가 10이 되면 돌지 않아야 한다. 따라서 mips에서 i가 10일 경우 분기하도록 beq $s0, $t0, done이 되어 있다. 또한 계속 돌기위해 for문 마지막에 다시 for문으로 분기하는 j 명령어가 있다.
22. Less Than 비교

먼저 볼 것은 loop에 있는 slt명령어이다. 이는 Set on less than의 약자로 slt $t1, $s0, $t0 dms 만약 $s0 < $t0이면 $t1에 1을 넣고 아니면 0을 넣으라는 것이다.
즉 slt a, b, c가 있으면 b와 c를 비교해 a값을 정하는 것이다.
또한 loop의 beq는 break코드로 이해하면 된다.
slt에서 i가 101보다 크거나 같으면 0을 넣기 때문에 beq에서 $t1이 0이면 분기하면 된다.
문제
1. MIPS assembly code로 add a, b, c가 있다. 여기서 목적지는 어디인지 쓰시오. ( )
2. MIPS assembly code로 add t, b, c sub a, t, d로 나타낼 때 이를 High-level code로 나타내시오.
( )
3. 이미지에 대한 설명으로 옳지 않은 것을 고르시오.
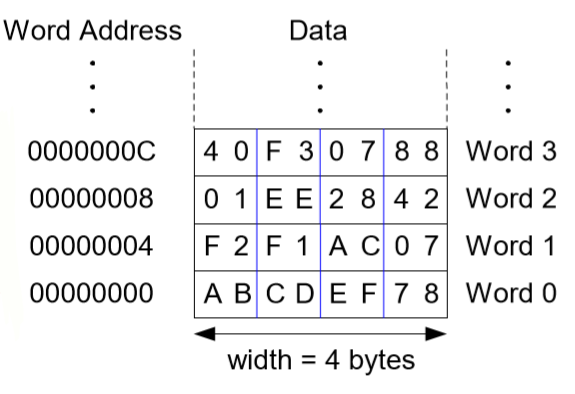
1) 바이트 주소 메모리이다.
2) lw명령어에서 가져오는 양은 1word로 정해져있다.
3) sw $t7, 12($0)은 워드주소 10진수 12에 $t7을 쓰라는 것이다.
4) 현재 1word당 4byte이다.
4. 보기를 리틀엔디안 시스템에서 수행한 후 $s0의 값을 구하시오.
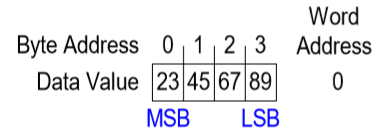
보기) sw $t0, 0($0) lb $s0, 2($0)
( )
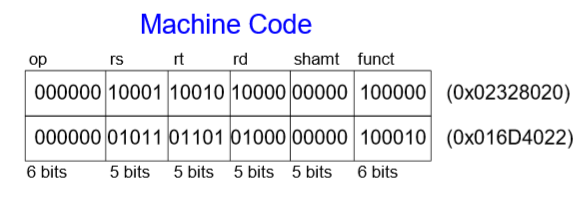
5. 어떤 명령어 형태인지 쓰시오. ( )
6. for루프를 MIPS assembly code로 나타내려고 한다. 빈칸에 들어갈 명령어를 쓰시오. ( )

7. High-level code를 MIPS assembly code로 바꾸려고 한다. 빈칸에 들어갈 내용을 쓰시오. ( )

답안
1. a
Mips 명령어는 첫 오퍼랜드가 목적지로 고정되어 있다.
2. a = b + c – d
add t, b, c 는 t = b + c의 코드이고, sub a, t, d 는 a = t - d의 코드 이기 때문에 위의 t를 밑에 대입하면 a = b + c - d가 된다.
3. 3
sw $t7, 12($0)은 워드주소 10진수 12에 $t7을 쓰라는 것이다. 에서 10진수 12가 아닌 10진수 12를 16진수로 바꾼 C에 쓰라는 것이다.
4. 45
위의 사진은 빅 엔디안 시스템이다. MSB에서 LSB로 주소가 증가하기 때문이다. 리틀엔디안 시스템은 LSB에서 MSB로 주소가 증가함으로 89, 67, 45, 23순서이다. 즉 2번 주소는 45이다.
5. R-Type
op코드가 0이므로 R-Type이다.
6. beq $s0, $t0, done
for문에서 i가 10이 아닐 동안 돌고 i가 10이면 나와야하기 때문에 i가 10이면 분기하게 만들면 된다.
즉 $s0과 $to이 같으면 done으로 분기하도록 beq 명령어를 써서 나타낸다.
7. beq $t1, $0, done
i가 101보다 작을 동안 돌아야 하고 i가 101보다 커지면 나와야한다.
slt에서 i가 101보다 크거나 같으면 0을 넣기 때문에 beq를 사용해서 $t1이 0이면 분기하도록 하면 된다.
출처
2019 컴퓨터 구조 호준원 교수님 강의노트 9
디지털논리와 컴퓨터 설계, Harris et al. (조명완 외 번역), 사이텍미디어, 2007
컴퓨터 구조와 원리 (비주얼 컴퓨터 아키텍쳐), 신종홍 저, 한빛미디어, 2011
'Computer Science (CS) > Computer Structure' 카테고리의 다른 글
| [컴퓨터구조 #7] 캐시 기억장치 (0) | 2020.06.02 |
|---|---|
| [컴퓨터구조 #6] 분기, 서브루틴 명령어와 명령어 분류 (0) | 2020.05.26 |
| [컴퓨터구조 #5] 메모리구조와 레지스터 (4) | 2020.05.23 |
| [컴퓨터구조 #4] 명령어 실행 기법 (2) | 2020.05.22 |
| [컴퓨터구조 #3] 컴퓨터 프로그래밍 언어 (0) | 2020.04.17 |