2주차에서 명령어 형식에 대해서 알아봤다.
3주차에서는 명령어를 효과적으로 실행하기 위한 기법을 다뤄보려고 한다.
명령어를 효과적으로 실행하기 위한 기법에는 주소 지정 방식, 파이프 라인 그리고 인터럽트가 있다.
1. 주소 지정 방식
주소란 주기억창치에서 데이터가 저장된 위치를 가리킨다. 주소 지정 방식은 주소를 지정하는 방식에따라 직접 주소 지정 방식, 간접 주소 지정 방식, 레지스터 주소 지정 방식, 레지스터 간접 주소 지정 방식, 변위 주소 지정 방식이 있다.
주소 지정 방식에서 쓰이는 내용과 그 내용에 대한 표기법을 알아보자.
| 정의 내용 | 표기 방법 |
| 유효 주소(기억장치의 실제 주소) | EA |
| 기억장치 주소 | A |
| 레지스터 번호 | R |
| 기억장치 A번지의 내용 | (A) |
| 레지스터 R번지의 내용 | (R) |
1-1. 직접 주소 지정 방식
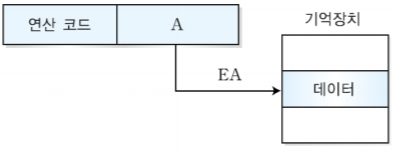
-가장 일반적인 개념의 간단한 주소 방식으로 주소 필드에 유효 주소를 직접 저장한다.
-유효주소가 기억장치 주소이며 EA=A로 나타낼 수 있다.
-특징: 화살표가 한 번만 있어서 한 번만 접근하기 때문에 데이터를 빠르게 가지고 올 수 있다는 장점이 있지만, 16비트의 명령어중에서 연산코드가 4비트를 차지하고 있을 경우 오퍼랜드는 총 길이에서 연산코드길이를 뺀 12비트만을 사용할 수 있기 때문에 2^12까지의 주소만 사용할 수 있어 제한적이라는 단점이 있다.
2-2. 간접 주소 지정 방식
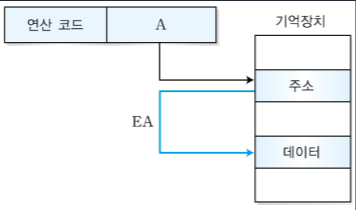
-유효주소가 기억장치 A의 내용이며 EA=(A)로 나타낼 수 있다. (A)는 포인터의 개념처럼 A라는 포인터가 가리키는 곳의 값이라고 이해하면 된다.
-직접 주소 지정 방식과는 다르게 기억장치에 두 번 접근한다. 처음 접근하는 곳은 유효주소의 주소를 가지고 있으며 두 번째로 접근하는 곳에는 실질적인 데이터가 있는 것이다.
-특징: 직접 접근 방식의 단점을 보완한 방식으로 오퍼랜드의 길이에 제한을 받지 않는다. 이 방식은 최대 기억장치 용량에 따라 활용할 수 있는 주소 공간을 확장할 수 있다. 따라서 긴 주소에 접근할 수 있다는 장점이 있다. 하지만 기억장치에 두 번 접근을 해야해서 직접 주소 지정 방식보다 속도가 느리며, 명령어 형식에서 주소 지정 방식을 표시하는 간접 비트 필드가 필요하다.

I가 0이면 직접 주소 지정 방식, 1이면 간접 주소 지정 방식이다.
1-3. 레지스터 주소 지정 방식
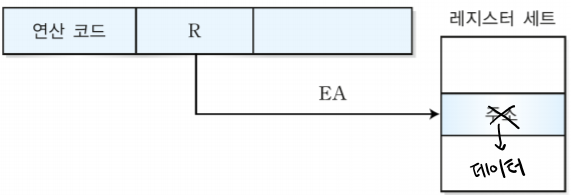
-오퍼랜드에 레지스터 번호가 저장되어 있으며 명령어 수행에 필요한 데이터가 해당하는 레지스터에 저장되어 있다. 주기억장치가아닌 레지스터에 데이터가 있다는 것이 중요하다.
-유효주소가 레지스터의 번호로 EA=R로 나타낼 수 있다.
-특징: 오퍼랜드 필드 비트수가 적어도 되며, 기억장치에 액세스 하지 않기 때문에 데이터 인출 시간이 적다는 장점이 있다. 하지만 데이터가 cpu내부의 레지스터에 저장되기 때문에 저장공간이 속도는 빠르지만 용량은 적은 레지스터로 제한된다.
1-4. 레지스터 간접 주소 지정 방식
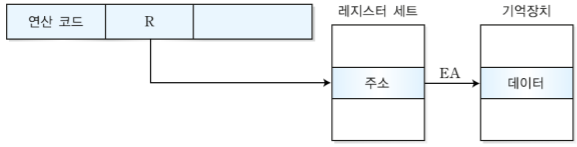
-레지스터에 저장된 것이 연산에 사용할 실질적인 데이터가 아닌, 그 데이터를 가진 기억장치의 주소이다.
-유효 주소가 레지스터에 저장된 내용을 가리키므로 EA=(R)로 나타낼 수 있다. 간접 접근 지정 방식과 마찬가지로 (R)은 R포인터가 나타내는 곳의 데이터라고 이해하면 된다.
-레지스터의 길이에 따라 주소지정 영역이 결정되는데, 만약 레지스터의 길이가 16비트라면 2^16까지의 주소를 지정할 수 있다.
-특징: 사용되는 레지스터 길이에 따라 많은 주소 공간을 사용할 수 있다는 장점이 있다. 하지만 주기억장치에 직접 2번 접근하는 간접 주소 방식과 달리 주기억장치에는 한 번만 접근해서 메모리 참조가 적게 일어나지만 주기억장치에 접근하기 전 레지스터에 접근해야하므로 여분의 메모리 참조가 필요하다는 단점이 있다.
1-5. 변위 주소 지정 방식
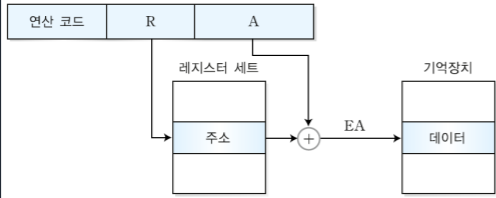
-직접 주소 지정 방식과 레지스터 간접 주소 지정 방식을 조합한 방식이다.
-유효주소가 R이 가리키는 레지스터의 내용과 변위 값 A를 더한 것으로 EA=(R)+A로 나타낼 수 있다. 따라서 두 필드의 조합으로 유효주소가 생성된다.
-16비트의 길이를 가진 레지스터는 2의 16승까지의 주소만 저장 가능하지만 변위값을 더하면 주소값을 더 많이 수용할 수 있기 때문에 이 방식을 사용한다.
-사용하는 레지스터에 따라 상대 주소 지정 방식, 인덱스 주소 지정 방식, 베이스 레지스터 주소 지정 방식으로 나눌 수 있다.
1-5-1. 상대 주소 지정 방식
-프로그램 카운터(PC)값을 사용한다.
-주로 분기 명령어에서 사용되는데 분기명령어는 JUMP와 CALL같이 다른 위치의 명령어로 분기시키는 명령어를 말한다.
-유효 주소는 프로그램 카운터의 내용과 기억장치의 주소를 더한 것으로 EA=(PC)+A로 나타낼 수 있다.
-예를 들어, 120번지에 저장된 JUMP 명령어가 인출된 후에, PC의 내용이 121이 된 경우 A가 +50dlaus 171번지가 되고, A가 -70인 경우 51번지가 된다. 여기서 A값을 음수로 사용할 수 있는 이유는 2의 보수로 음수값이 표현가능하기 때문이다.
1-5-2. 인덱스 주소 지정 방식
-인덱스 레지스터를 사용한다. 인덱스 레지스터란 인덱스 값을 저장하는 특수 레지스터이다.
-유효 주소는 인덱스 레지스터의 내용과 기억장치 주소를 더한 것으로 EA=(IX)+A로 나타낼 수 있다.
-특징: 명령어가 실행될 때마다, 인덱스 레지스터의 내용이 자동적으로 증가 또는 감소하기 때문에 for문 같은 루프 프로그램에서 동일한 명령어를 사용해 배열내의 데이터에 접근하여 연산하는데 효율적으로 사용될 수 있다. 만약 명령어가 실행된다면 EA=(IX)+A와 IX<-IX+1이 연속적으로 수행된다.
1-5-3. 베이스 레지스터 주소 지정 방식
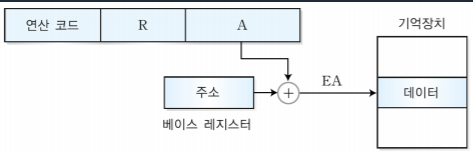
-베이스 레지스터를 사용한다.
-유효 주소는 베이스 레지스터의 내용과 기억장치 주소를 더한 것으로 EA=(BR)+A로 나타낼 수 있다.
2. 명령어 파이프 라인
-하나의 명령어를 여러 단계로 나누어서 단계별로 동시에 수행하여 처리 속도를 향상 시키는 방법이다.
-몇 단계로 나누냐에 따라 2단계, 4단계, 6단계 명령어 파이프라인으로 나눌 수 있다.
-파이프 라인 예시로 좋은 세탁기가 있는데, 세탁물 1, 2, 3이 있다고 하자, 이때 세탁물1의 빨래, 건조, 정리가 다 끝나고 세탁물2를 빨래, 건조, 정리하고 끝나면 또 세탁물3 빨래를 시작하면 시간이 오래걸리며 상당히 비효율적이다. 세탁기, 건조기와 내가 있기 때문에 세탁물이 1개가 모든 과정이 끝날 때까지 기다릴 필요없이 각각 자기 할 일을 수행하면 시간이 훨씬 단축되며 효율적이다.
-파이프 라인은 클록 주기라는 것을 사용하는데 이는 cpu가 명령어를 처리하는 주기이다.
2-1. 2단계 명령어 파이프 라인
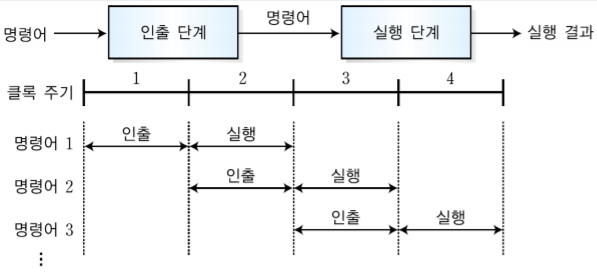
-명령어를 인출 단계와 실행 단계라는 두 개의 독립적인 파이프라인 모듈로 분리해서 수행한다. 인출 단계에서 명령어 몇개를, 실행 단계에서 명령어 몇개를 동시에 수행하는 것이 아닌, 인출 단계에서 1개, 실행 단계에서 1개를 동시에 수행할 수 있다는 것이다.
-여기서 명령어 1이 들어가면 먼저 인출 단계를 거친다. 이때, 실행 단계는 아무 것도 수행하고 있지 않는다. 명령어 1이 인출 단계가 끝나면 실행 단계로 들어가게 되는데 그렇게 되면 인출 단계는 아무 것도 안하고 있으니 명령어 2를 받아서 수행한다. 이런식으로 각각의 명령어는 다음 명령어를 받아서 수행한다.
-주의할 점은 인출 단계를 거쳐야 실행 단계로 넘어갈 수 있다는 것이다.
2-2. 4단계 명령어 파이프 라인
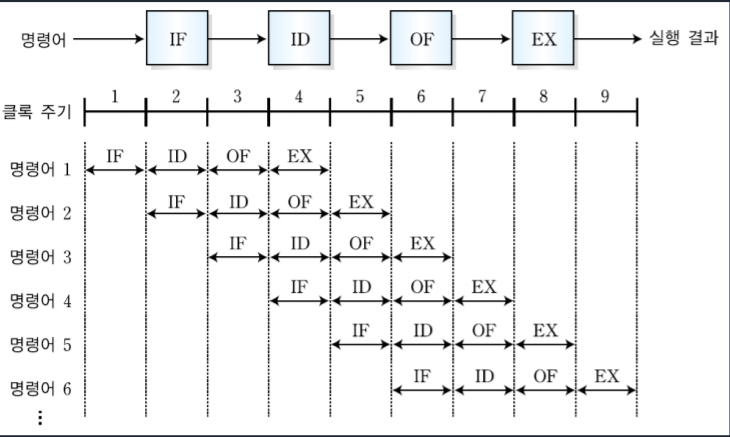
-명령어 인출(IF), 명령어 해독,(ID) 오퍼랜드 인출(OF, 실제 데이터를 인출함), 실행(EX) 이렇게 4단계로 구성된 파이프 라인이다.
-2단계 파이프 라인처럼 명령어 인출이 끝나고 명령어 해독 단계로 넘어가면 다음 명령어가 명령어 인출을 시작한다. 클록 주기에서 '4'자리에 보면 명령어1은 4단계, 명령어2는 3단계, 명령어3은 2단계, 명령어4는 1단계를 동시에 수행하고 있는 것을 볼 수 있다.
2-3. 6단계 명령어 파이프 라인
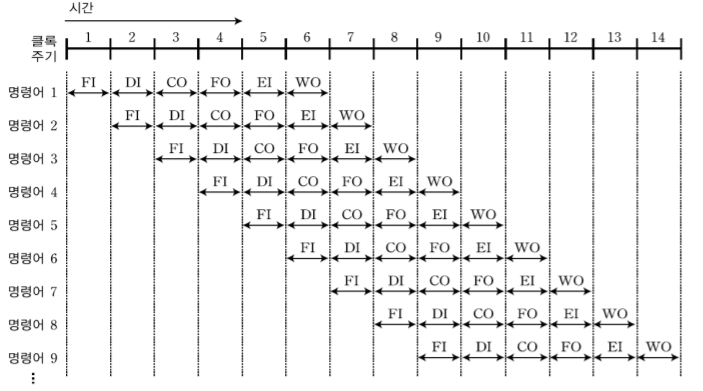
-명령어 인출(FI), 명령어 해독(DI), 오퍼랜드 계산(CO), 오퍼랜드 인출(FO), 명령어 실행(EI), 오퍼랜드 저장(WO) 이렇게 6단계로 구성된 파이프 라인이다.
-2,4단계 파이프 라인과 마찬가지로 하나의 단계가 끝나면 다음 명령어가 그 단계에서 바로 수행된다. 클록 주기에서 '9'자리에 보면 명령어 4는 6단계, 5는 5단계, 6은 4단계 이런식으로 6단계가 각각 다른 명령어를 동시에 수행하고 있다.
*여기서 흥미로운 점은 4단계와 6단계의 같은 단계라도 영어가 다르다는 것이다.
| 단계 명 | 4단계 | 6단계 | ||
| 명령어 인출 | Instruction Fetch | IF | Fetch Instruction | FI |
| 명령어 해독 | Instruction Decode | ID | Decode Instruction | DI |
| 오퍼랜드 계산 | X | X | Calculate Operand | CO |
| 오퍼랜드 인출 | Operand Fetch | OF | Fetch Operand | FO |
| 명령어 실행 | Execute | EX | Execute Instruction | EI |
| 오퍼랜드 저장 | X | X | Write Operand | WO |
2-4. 파이프 라인에 의한 속도 향상
-명령어 실행 시간 계산
| k | 파이프 라인 단계 수(2단계는 2, 4단계는 4, 6단계는 6) |
| N | 실행할 명령어들의 수 |
| 각 파이프라인의 단계 | 한 클록 주기씩 소요됨 |
| T | 파이프라인을 적용했을 때, N개의 명령어를 실행하는 데 소요되는 시간 |
| T = k + (N - 1) | |
| T | 파이프라인을 적용하지 않았을 때, N개의 명령어를 실행하는 데 소요되는 시간 |
| T` = k * N | |
-먼저 T = k + (N - 1)의 식을 해석해보자면, k는 첫 번째 명령어를 실행하는 시간이며, (N - 1)은 첫 번째 명령어를 뺀 나머지 명령어들이 소요되는 시간이다. 1*(N - 1)에서 1*을 생략했다고 생각하면 된다.
4단계 파이프라인을 예시로 들어보자.
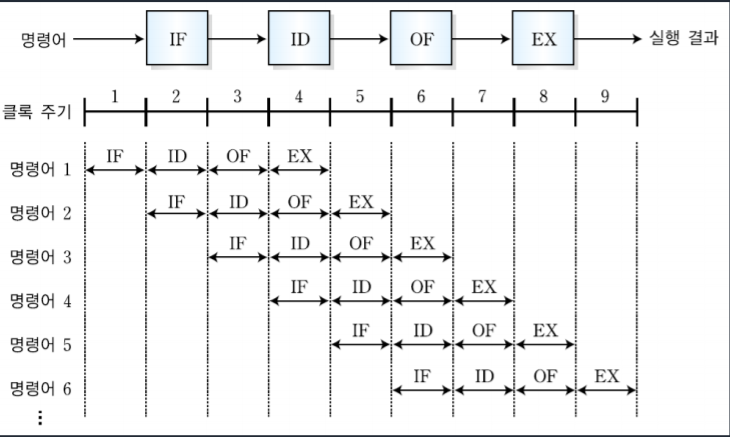
클록 주기를 초단위로 생각해보면 명령어 1은 4초가 걸리고 나머지 명령어들은 1초씩만 사용한다고 생각할 수 있다. 따라서 4단계 파이프 라인에서 명령어 6개 실행시간 T는 명령어 1이 수행되는 시간 4 + 총 명령어 6에서 1을 뺀 값인 5을 하면 9가 된다.
이와 달리 파이프라인을 적용하지 않았을 경우에는 명령어 1개당 4개의 단계씩 거치지 때문에 명령어 총 개수 * 단계 수를 하면된다. 따라서 파이프 라인을 적용하지 않고 명령어 6개를 실행하는 시간은 4 * 6 = 24이다.
이 둘을 가지고 파이프 라이닝에 대한 속도 향상도 알 수 있는데 파이프 라이닝 하지 않고 소요된 시간 / 파이프 라이닝하고 소요된 시간 즉, T` / T로 나타낼 수 있으며 여기서는 24 / 9 해서 약 2.27배의 속도 향상이 있었다고 말할 수 있다.
3. 인터럽트
-cpu가 현재 실행 중인 프로그램의 처리를 강제적으로 중단시키고, 특정 주소에 위치한 프로그램을 수행하는 것이다.
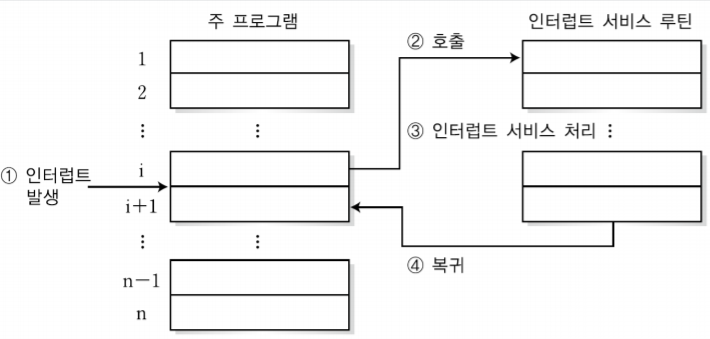
3-1.동작원리
인터럽트 서비스 루틴(ISR, Interrupt Service Routine): 인터럽트를 처리하기 위해 실행되는 프로그램 루틴이다.
인터럽트가 발생하면 현재 실행하고 있던 프로그램의 중요한 데이터는 주기억장치에 저장되며 중지된다. 중지 된 후 인터럽트 서비스 루틴이 처리하는 프로그램이 종료된 후에 다시 재개된다. 예를 들어 어떤 유튜브 영상을 보고 있는데 친구에게 카톡이 와서 카톡을 확인한 후 다시 유튜브로 가서 아까 보다 멈춘 곳 부터 다시 보는 것이 있다.
3-2. 인터럽트 종류와 발생 원인
1)전원 이상 인터럽트(Power Failed Interrupt): 정전이 되거나 이상이 있는 경우 발생한다.
2)기계 착오 인터럽트(Machine check interrupt): CPU의 기능적인 오류로 발생한다.
3)입출력 인터럽트(I/O Interrupt): 입출력 데이터의 종료나 오류에 의해 cpu기능이 요청되는 경우 발생하며 예로 사용자 입력 요청을 보냈을 때 사용자의 입력이 끝날 때까지 다음 명령어를 수행안하는 것을 들 수 있다.
4)외부신호 인터럽트(External Interrupt): 오퍼레이터나 타이머에 의해 의도적으로 프로그램이 중단된 경우 발생하며 타이머에 의해 설정된 시간을 알리는 경우나 외부 장치로부터 인터럽트 요청이 있는 경우가 있다.
5)프로그램 검사 인터럽트(Program Check Interrupt): 오버플로우나 0에 의한 나누기, 프로그램에서 명령어 잘못사용하는 경우처럼 프로그램 실행 중 보호된 기억공간 내에 접근하거나 불법적인 명령 수행으로 발생한다.
6) 슈퍼바이저 호출 인터럽트(Supervisor Call Interrupt): 사용자가 슈퍼바이저 호출(SVC) 명령어를 써서 운영체제에 서비스를 요청하거나 복잡한 입출력 처리를 해야하는 경우 발생한다.
7)재시작 인터럽트(Restart Interrupt): 콘솔 상에서 재시작 버튼이나 Ctrl-Alt-Del키를 누른 경우 발생한다.
3-3. 인터럽트 사이클
-인터럽트 발생을 처리하기 위한 사이클로 cpu가 인터럽트 요구의 존재 여부를 검사한다.
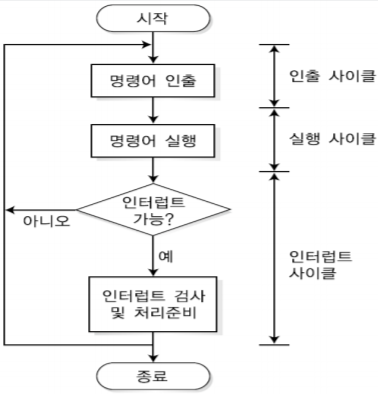
만약 인터럽트 발생이 없으면 다음 명령어를 인출하면 되지만 인터럽트 요구가 대기 중이면, 진행하고 있던 프로그램을 중단 한 후, 프로그램 상태에 저장한다. 이후 프로그램 카운터를 인터럽트 처리 루틴의 시작 주소로 설정하고 인터럽트를 처리한다.
인터럽트를 처리하기 위해서는 현재 프로그램의 데이터를 저장해야 인터럽트가 끝난 후 다시 재개할 수 있으며 프로그램 카운터를 인터럽트 주소로 해야 다음 명령어 대신 인터럽트를 수행할 수 있다.
3-4. 다중 인터럽트 처리
다중 인터럽트란 인터럽트 서비스 루틴을 수행하는 동안 또 다른 인터럽트가 발생한 것이다. 이 때는 원래 실행하고 있던 인터럽트가 끝난 후에 처리할 지, 또 다른 인터럽트가 발생한 순간 처리하고 원래 실행하던 인터럽트를 처리할 지의 문제가 발생하기 때문에 다중 인터럽트 처리하기 위한 2가지 방식이 있다.
-순차적인 다중 인터럽트 처리
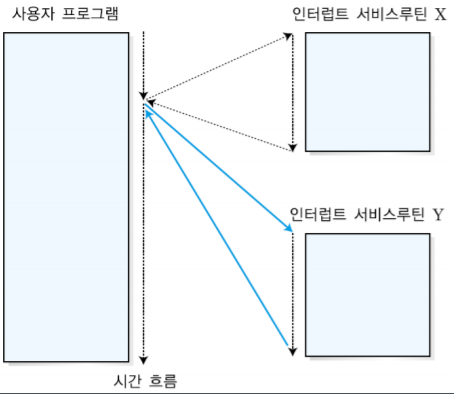
원래 발생했던 x를 처리한 후 y를 처리하는 방식이다. x를 처리할 동안 y는 대기상태에 있다.
-우선순위 다중 인터럽트 처리
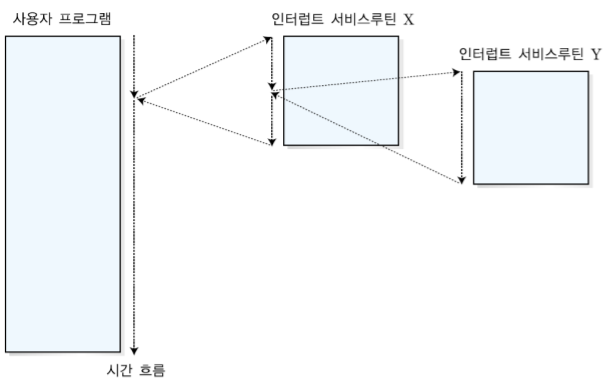
인터럽트의 우선 순위를 정한 후, 만약 x 우선순위가 높다면 x가 끝난 후 y를 처리하고, y의 우선순위가 높다면 x를 잠시 중단한 후 y를 처리하고 다시 x를 재개한다.
*우선순위
전원 이상(Power fail) > 기계 착오(Machine Check) > 외부 신호(External) > 입출력(I/O) > 명령어 잘못 > 프로그램 검사(Program Check) > SVC(SuperVisor Call)
문제
1. 기억장치에 두 번 접근하여 데이터를 가져오는 방식 종류로 알맞은 것은?
1) 직접 주소 지정 방식
2) 간접 주소 지정 방식
3) 레지스터 간접 주소 지정 방식
4) 변위 주소 지정 방식
2. EA=R로 나타낼 수 있는 주소 지정 방식은?
( )
3. 변위 주소 지정 방식에서 프로그램 카운터 값을 사용하는 방식은?
1) 상대 주소 지정 방식
2) 인덱스 주소 지정 방식
3) 레지스터 주소 지정 방식
4) 베이스 레지스터 주소 지정 방식
4. 6단계 명령어 파이프 라인을 적용했을 때 15개의 명령어를 실행하는 데 소요되는 시간은?
( )
5. 4단계 명령어 파이프 라인에서 파이프 라인을 적용하지 않았을 때 20개의 명령어를 실행하는 데 소요되는 시간은?
( )
6. 2단계 명령어 파이프 라인을 적용했을 때 6번째 명령어가 실행되는 시점은? (클록 주기를 기준으로 한다.)
( )
7. ( )가 발생하면 현재 실행하고 있던 프로그램의 중요한 데이터는 주기억장치에 저장되며 중지된다. 괄호안에 알맞은 용어를 쓰시오.
8. 0에 의한 나누기로 발생하는 인터럽트의 종류는?
1) 기계 착오 인터럽트
2) 입출력 인터럽트
3) 외부신호 인터럽트
4) 프로그램 검사 인터럽트
9. 우선순위 다중 인터럽트처리에서 만약 외부신호 인터럽트를 실행하는 도중 기계 착오 인터럽트가 나타났을 경우 먼저 실행되는 것은 기계 착오 인터럽트이다. (o / x)
10. 5개의 명령어를 4단계 파이프 라인으로 실행했을 때 실행하지 않았을 때보다 속도는 얼마나 향상되는지 계산하시오.
( )
답안
1. 2
직접 주소 지정 방식은 기억장치에 한 번 접근하며, 레지스터 간접 주소 지정 방식과 변위 주소 지정 방식은 레지스터에 한 번, 기억장치에 한 번 접근한다.
2. 레지스터 주소 지정 방식
유효주소가 레지스터의 번호이다. 그 레지스터에는 실질적인 데이터가 들어있다.
3. 1
인덱스 주소 지정 방식은 인덱스 값을 저장하는 특수 레지스터인 인덱스 레지스터를 사용하고 레지스터 주소 지정 방식은 레지스터를 사용하며 베이스 레지스터 주소 지정 방식은 베이스 레지스터를 사용한다.
4. 20
파이프 라인을 적용할 경우 명령어 실행 시간 T는 파이프 라인의 단계 수 k + 실행할 명령어 수 N – 1 즉 T = k + (N – 1)로 나타낼 수 있다. 따라서 T = 6 + 15 – 1이므로 20이다.
5,. 80
파이프 라인을 적용하지 않을 경우 명령어 실행 시간 T`는 파이프 라인의 단계 수 k * 실행할 명령어 수 N 즉 T` = k * N으로 나타낼 수 있다. 따라서 T` = 4 * 20으로 80이다.
6. 6
명령어 파이프 라인을 적용할 경우 n번째 명령어는 단계에 상관 없이 n번째 클록에서 시작된다. 첫 번째 단계가 명령어를 하나씩 처리하기 때문이다. 따라서 6번 째 명령어는 6번째 클록에서 시작된다.
7. 인터럽트
8. 4
기계 착오 인터럽트는 cpu의 기능적인 오류로 발생하며, 입출력 인터럽트는 입출력 데이터의 종료나 오류에 의해 나타나고, 외부신호 인터럽트는 오퍼레이터나 타이머 또는 외부장치로부터 요청이 오면 발생한다.
9. O
다중 인터럽트가 발생할 경우 우선 순위 다중 인터럽트 처리에서는 우선 순위가 높은 인터럽트부터 먼저 처리하는데 기계 착오 인터럽트가 외부 신호 인터럽트보다 높기 때문에 먼저 수행된다.
10. 2.5
문제 5, 6의 해설을 보면 명령어 파이프 라인을 실행한 경우, 실행하지 않은 경우에 대한 시간 공식을 알 수 있다. 파이프 라인 실행한 경우 속도 T는 4 + (5 - 1)로 8이며 파이프 라인 실행하지 않은 경우 속도 T`는 4 * 5로 20이다. 20 / 8하면 2.5배 향상된 것을 알 수 있다.
'Computer Science (CS) > Computer Structure' 카테고리의 다른 글
| [컴퓨터구조 #6] 분기, 서브루틴 명령어와 명령어 분류 (0) | 2020.05.26 |
|---|---|
| [컴퓨터구조 #5] 메모리구조와 레지스터 (4) | 2020.05.23 |
| [컴퓨터구조 #3] 컴퓨터 프로그래밍 언어 (0) | 2020.04.17 |
| [컴퓨터구조 #2] 컴퓨터 정보의 표현과 논리연산 (0) | 2020.04.17 |
| [컴퓨터구조 #1] 중앙처리장치(CPU) (0) | 2020.04.11 |