Type1과 Type2는 Hypervisor를 어떠한 형태로 개발할 것이냐에 따라 나뉜다.
Type1은 하이퍼바이저는 OS 형태로 개발한다. 하이퍼바이저가 하드웨어 바로 위에서 실행되며 하이퍼바이저가 하드웨어를 직접 제어하기 때문에 자원을 효율적으로 사용할 수 있고, 별도의 Host OS가 없어서 오버헤드가 적지만 여러 하드웨어 드라이버가 필요해서 설치가 어렵다.
Type2는 하이퍼바이저는 Application 형태로 개발한다. 호스트형 하이퍼바이저는 일반적인 소프트웨어처럼 Host OS 위에서 실행된다. 이는 하드웨어 자원을 VM 내부의 guest OS에 에뮬레이트하는 방식이기 때문에 Type1보다 오버헤드가 크지만 게스트 OS 종류에 대한 제약이 없다. 또한 하이퍼바이저가 application으로 취급되기 때문에 만약 다른 application에서 악성코드가 실행될 경우 문제를 전달받을 수 있다.
이는 사용료를 지불하면서 빌려쓰는 방식으로 IT 자원에 대한 구매가 아닌 '구독'을 하고 사용한 만큼 사용료를 지불한다.
따라서 초기 토자 비용이 절감되기도 한다. 또한 클라우드는 정기적인 최신 성능 업그레이드가 이루어지기 때문에 시설 노후화에 대한 부담 감소가 있다. 그리고 OPEX 기반 환경이므로 CAPEX가 적고 특정 기업에 갇힐 확률이 적다.
하지만 클라우드에서 정보 유출 사고가 발생할 경우 detect가 힘들고 인터넷이 어떻게 끊길지 모른다는 단점이 있다.
이는 대체로 규모가 중-소인 기업에 적절하다.
📌 Private cloud
프라이빗 클라우드는 자신의 온프레미스(on-premise)내에 클라우드 플랫폼을 구축해서 운영한다.
자체적으로 보안 시스템을 운영할 수 있고, 사용자의 필요와 요구에 따라 맞춤형 구축이 가능하다는 장점이 있다.
하지만 설치운영 비용인 CAPEX가 생기고 관리를 위한 전문가 고용이 필요하다는 단점이 있다. 또한 특정 기업에 갇힐 확률이 크다.
이는 규모가 큰 비지니스에 적절하다.
📌 Hybrid cloud
하이브리드 클라우드는 public과 private cloud를 혼합한 형태이다. 보안이 중요한 것은 private cloud로, 신규 서비스나 이벤트 등 예측하기 어려운 대용량 데이터는 신속하게 자원을 확장할 수 있도록 public cloud에 배치하는 것이다. 이는 퍼블릭 클라우드의 유연성과 확장성, 비용 효율성을 누리면서 보안 걱정을 덜 수 있다.
x86 CPU 시뮬레이터를 통해 race condition과 test-and-set을 비교해서 race condition에 대해 분석하고 문제에 대한 답변을 작성하는 것이다.
그렇다면.. race condition이란?
경쟁 상태라고도 하며 두 개 이상의 프로세스가 공통 자원을 사용할 때, 타이밍이나 순서에 따라 시스템 결과값이 달라지는 것을 말한다.
race condition은 디버깅 할 때는 문제점을 찾을 수 없고, 늘 항상 같은 결과값을 보장하지 못하므로 치명적인 문제가 발생할 수 있다.
따라서 동시성 이슈를 해결해줘야한다.
📌 실습 환경
Ubuntu OS가 설치된Linux 실습환경
Python버전 2.x 이상 (Python 3 아님에 주의!)
📌 분석에 필요한 파일
교수님께서 깃허브 링크를 주셔서 clone 받은 후 실습을 진행했다. 깃헙 링크를 첨부하기가.. 조금 그래서 파일 명을 가지고 설명해보도록 하겠습니다.
x86.py
race.s (race condition 발생 o)
test-and-set.s (race condition 발생 x)
여기서 x86.py는 x86 시뮬레이터 파일이며, race.s와 test-and-set.s은 count 변수의 값을 1 증가시키는 어셈블리 instruction 코드이다.
📌 결과값 예시
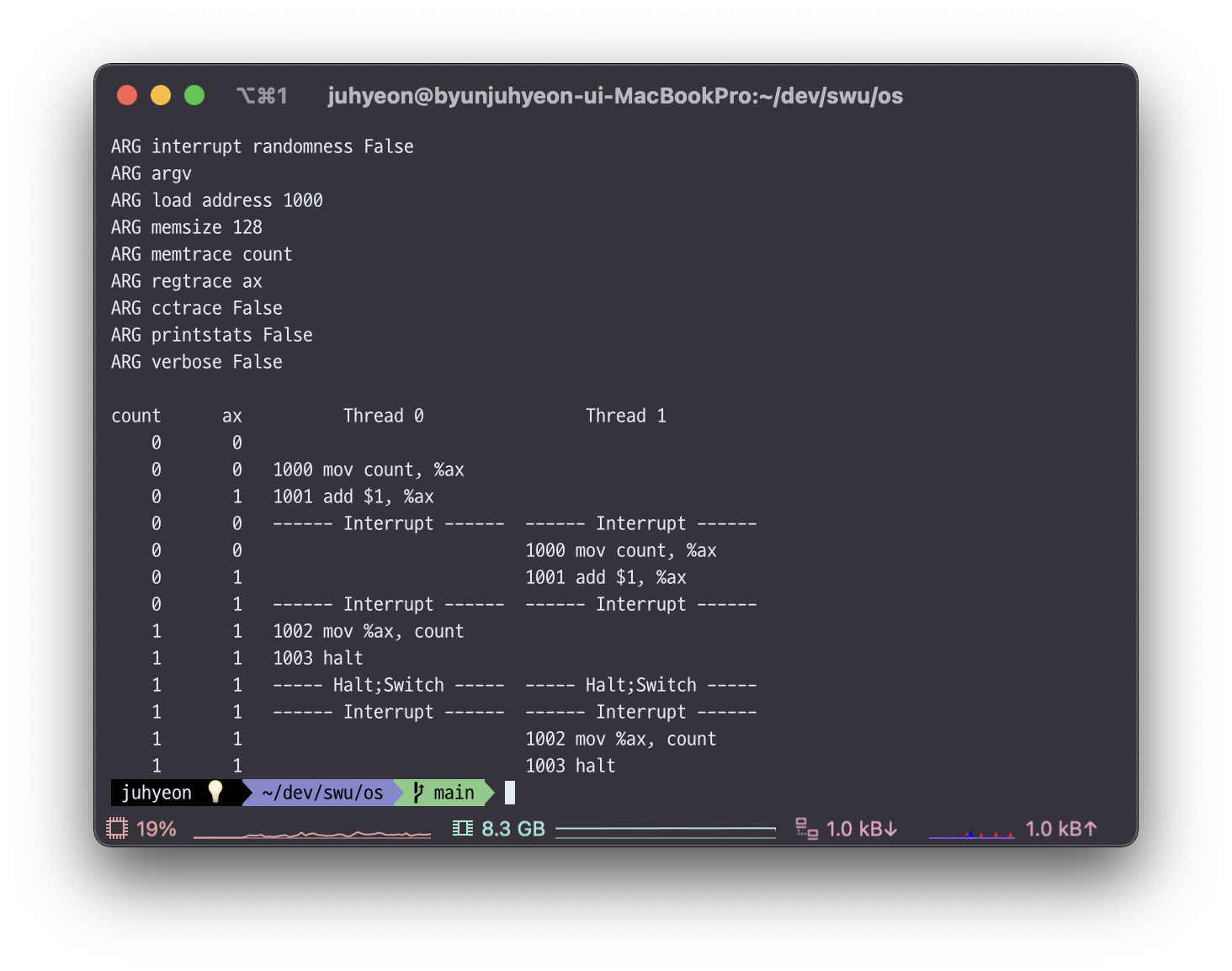
인터럽트가 걸리지 않은 상태
왼쪽의 count는 변수, ax는 레지스터이며 Thread 0, Thread 1은 공통된 자원(count)를 공유하는 쓰레드이다.
현재는 인터럽트가 아무 것도 걸리지 않았으므로 Thread 0에서 count값을 1 더해주고, Thread 1이 1이 저장된 count값을 받아 1을 더해주었다. 따라서 최종 결과값은 count가 2인 것을 볼 수 있다.
만약, 이 코드에서 인터럽트가 걸려서 코드의 타이밍이 변경된다면 결과값이 달라질 수도 있을 것이다.
📌 race.s 코드에서 인터럽트 빈도가 1 또는 2라면?
인터럽트 빈도가 1인 경우인터럽트 빈도가 2인 경우
두 실행 결과 모두 count값이 1이 된다.
인터럽트 빈도가 1이나 2일 때는 Thread 0에서 ax값을 count에 저장하는 코드가 실행되기 직전에 인터럽트가 걸린다.
이 경우에는 count값이 공유되는 데이터이므로 Thread1이 1000번 명령어인 count값을 ax레지스터로 가지고 올 때 1로 바뀌지 않고 아직 0으로 셋팅된 count값을 가지고 오기 때문에 문제가 된다.
즉 Thread0에서 ax에 1을 더하는 것과 ax값을 count에 넣는 코드가 연달아 실행되지 않아서 Thread1은 변경되지 않은 count 값을 가지고 명령어를 수행하기 때문에 최종 count값이 1이된다.
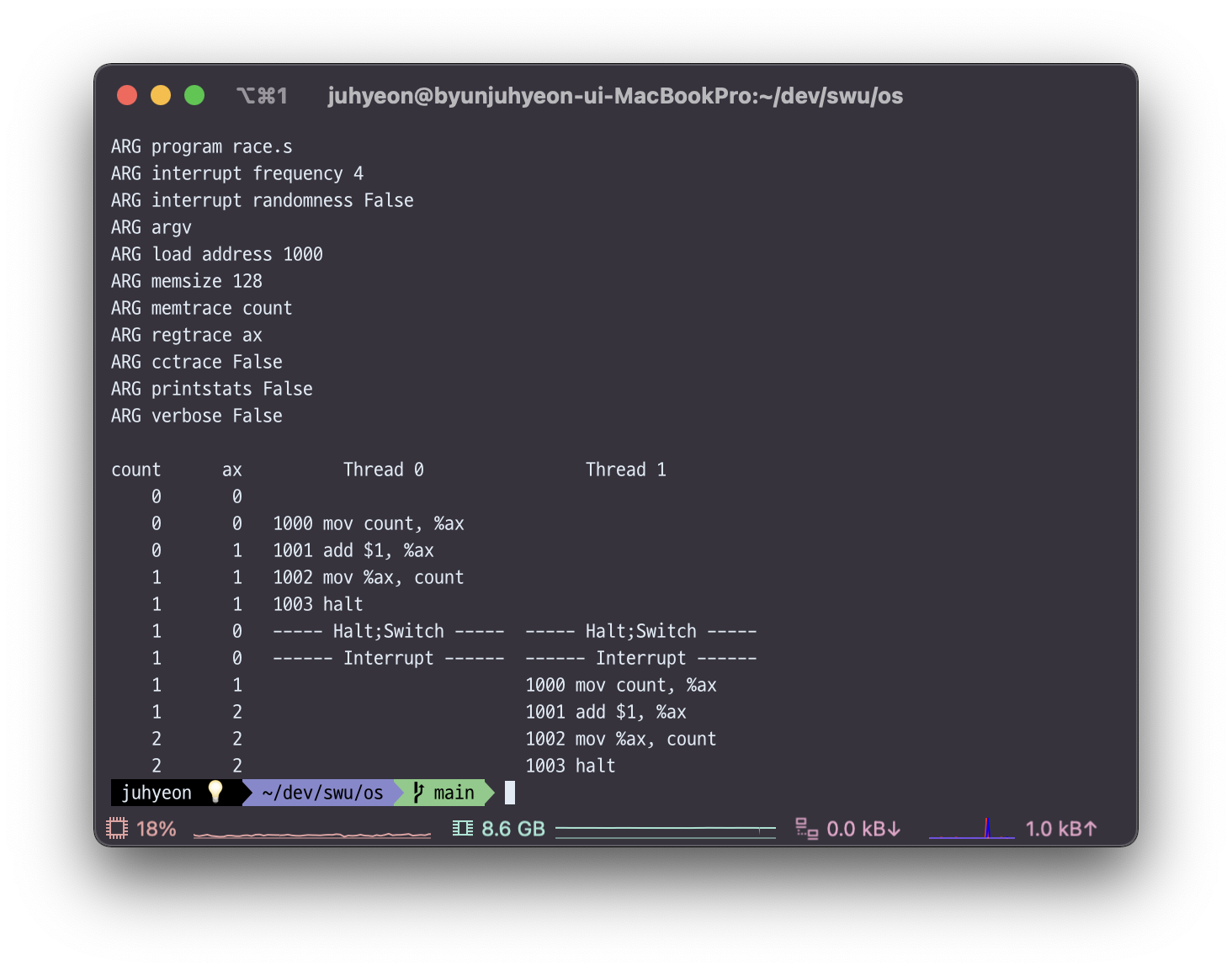
📌 race.s 코드에서 인터럽트 빈도가 3이상이라면?
인터럽트 빈도가 3일 경우인터럽트 빈도가 4일 경우
인터럽트 빈도가 3 이상이라면 count 값은 결과적으로 2가 나온다.
인터럽트 빈도가 3이나 4일 때, 그리고 5이상(Thread0의 코드가 이미 끝난 경우)일 때에는 인터럽트 빈도가 2 이하일 경우와는 다르게 1001, 1002번 명령어인 ax에 1을 더하는 것과 ax값을 count에 저장하는 코드가 연달아 수행되기 때문에 최종 count값은 2가 된다.
📌 race.s 코드의 race condition 문제점
ax 레지스터에 각 스레드의 결과를 저장하는 부분이 올바른 타이밍에 실행되지 않으면 결과값이 달라지는 치명적인 문제가 발생한다.
이 코드에서는 1001, 1002번 명령어가 한 번에 실행되지 않을 경우에 해당하는 것이다.
따라서 인터럽트 빈도가 1 또는 2일 경우에 count 결과값이 달라지므로 race condition 문제가 발생한다고 볼 수 있다.
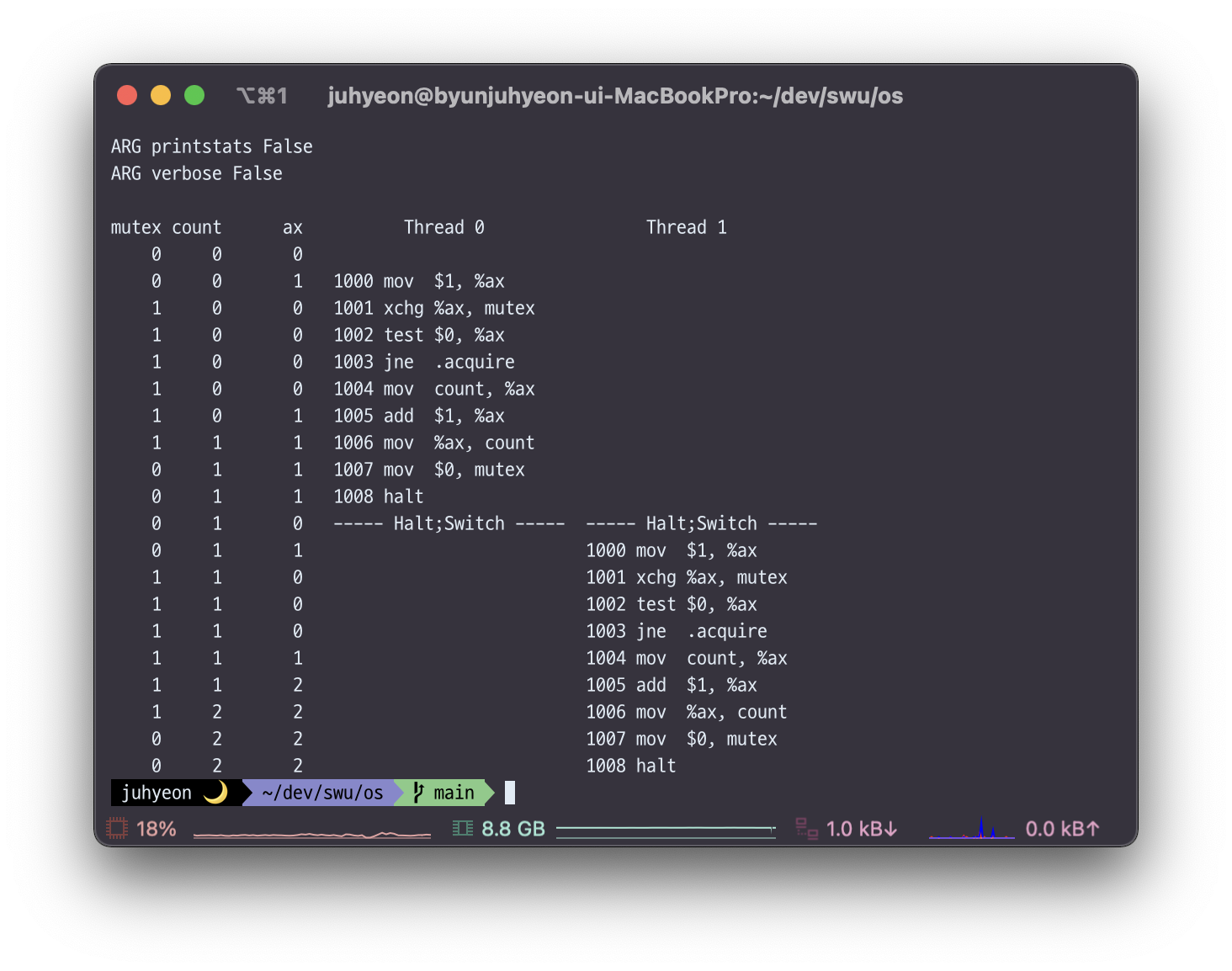
📌 test-and-set.s 코드에서 인터럽트 빈도에 따른 count 값은?
test and set 코드
위 사진은 test-and-set.s를 인터럽트 없이 실행시킨 코드이다.
이 코드는 아까 race.s 코드와는 다르게 인터럽트 빈도를 다양하게 걸어도 race condition 문제가 발생하지 않는다.
먼저 count와 mutex는 공유되는 데이터, ax는 각각이 가진 레지스터이다.
여기서 mutex값은 lock을 걸어줬는지 아닌지를 알 수 있는 데이터로 사용된다.
실행결과를 보면 1004번 명령어가 현재 count값을 자신의 ax레지스터로 가져오는 명령어이다. 이 명령어가 제대로 변경된 후의 count값을 가지고 오면 문제가 없을 것이다.
이 코드에서 인터럽트가 상관없는 이유는 1004번 이전의 명령어와 1007번 명령어 때문이다.
Thread1은 인터럽트를 걸고 ax값을 1로 셋팅해서 현재의 mutex값과 비교한다. Thread0이 count값을 가져오고(1004) ax에 1을 더하고(1005), ax를 count에 저장하는(1006) critical section에 해당하는 코드를 실행하기 직전에 mutex값을 1로 셋팅하기 때문에 Thread1은 mutex값을 보고 1이면 Thread0이 아직 critical section코드를 수행하고 있다고 알 수 있기 때문에 다시 1000번 명령어로 점프하게 된다.
즉, 인터럽트가 언제 걸리든 항상 Thread1은 mutex값 비교를 통해 Thread0이 count값 저장을 끝냈는지를 알 수 있다. 따라서 Thread0이 1증가된 ax값을 count에 저장하는 코드인 1006번 코드가 끝나고 mutex값을 다시 0으로 변환해주기 전까지는 Thread1이 1000번 코드로 게속 점프하게 된다. 만약 검사 했을 때 mutex값이 0이라면 Thread1에서는 더이상 1000번코드로 점프하지 않고(검사하지 않고) 비로소 1004번 코드로 넘어가게 된다.
이 코드에서 mutex값을 1로 바꿔주는 것은 critical section전 lock을 거는 것이고 mutex값을 0으로 바꿔주는 것은 lock을 해제한다는 의미를 가진다. 따라서 Thread1은 lock이 걸린지 아닌지를 확인하고 lock이 해제될 때까지 기다리다가 해제되었다고 판단되면 현재 count값을 가지고 와서 다음 명령어들을 실행한다.
결론적으로 Thread1은 count값이 1로 변경되고 나서 가지고 오기 때문에 최종 결과값은 인터럽트 빈도에 상관없이 2가 된다.
-MIPS는 S(Microprocessor without interlocked pipeline stage의 약자로 컴퓨터 분야에서 밉스 테크놀로지에서 개발한 축소 명령 집합 컴퓨터(RISC)의 구조 및 그 구조를 이용한 마이크로프로세서임. -1980년대 스탠포드대학에서 John Hennessy와 그의 동료들에 의해 개발됨 -Silicon Graphics, Nintendo, Cisco의 제품에서 사용되고 있음
2. 디자인 원리
-규칙적인 것이 간단성을 위해 좋음 -많이 발생되는 사항을 빨리 처리함 -적을수록 빠름 -좋은 설계는 좋은 절충안을 요구함
3. 설계 원칙 1
규칙적인 것이 간단성을 위해 좋음
-일관성있는 명령어 형태 -같은 수의 피연산자 (두 개의 source와 한 개의 destination) -하드웨어로 구현하기 쉬움
명령어는 Addition(덧셈)과 Subtraction(뺄셈)뿐이다.
-Addition(덧셈) a = b + c 는 밉스 어셈블리 코드로 add a, b, c 로 나타낼 수 있다. 여기서 add는 연산코드이며, a는 목적지, b와 c는 각각 소스1, 2이다. 밉스 어셈블리 코드에서는 무조건 destination코드 위치가 정해져있음을 주의한다.
-Subtraction(뺄셈) a = b - c 는 밉스 어셈블리 코드로 sub a, b, c 로 나타낼 수 있다. 덧셈과 같이 sub는 연산코드, a는 목적지, b와 c는 각각 소스1, 소스2이다.
4. 설계 원칙 2
많이 발생되는 사항을 빨리 처리함
-MIPS: 단순하고, 많이 사용되는 명령어를 포함 -명령어를 해석하고 실행하는 하드웨어: 단순하고 빠름 -복잡한 명령어는 여러개의 단순한 명령어로 수행됨
명령어 한 줄을 처리하는 데 시간이 단축되어 빠르다는 장점이 있다.
컴퓨터 구조 분류
RISC (Reduced Instruction Set Computer): MIPS CISC (Complex Set Instruction Set Computer): Intel의 IA-32
복잡한 코드: 여러개의 MIPS 명령어에 의해 처리됨
a = b + c - d 는 add t, b, c 와 sub a, t, d 라는 두 개의 밉스 명령어를 사용한다. 먼저 add t, b, c 는 t = b + c 라는 의미이며 sub a, t, c는 앞서 나온 결과 값 t를 이용하여 a = t - d 라는 의미이다. 즉 t 대신 b + c 를 넣으면 a = b + c - d 이기 때문에 같다.
5. 설계 원칙 3
적을수록 빠름
-MIPS: 적은수의 레지스터를 포함 -32개의 레지스터 (32 비트 또는 64 비트) -32개의 레지스터로 부터 데이터를 획득하는 것이 1000개의 레지스터 또는 메모리로 부터 데이터를 획득하는 것 보다 빠름
a = b + c 는 $s0 = a, $s1 = b, $s2 = c 일 때, add $s0, $s1, $s2 한 것과 같다. a = b + c - d 는 $s0 = a, $s1 = b, $s2 = c, $s3 = d 일 때, sub $t0, $s2, $s3 와 add $s0, $s1, $t0 를 한 것과 같다.
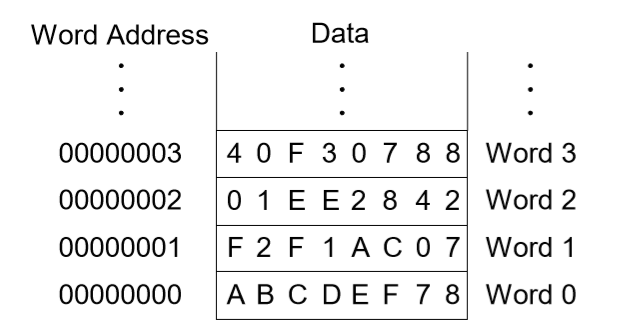
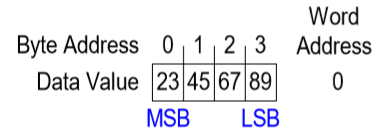
8. 워드(word) 주소 메모리
1워드 차이가 주소에서 1씩 차이난다.
-load 명령어 (lw)
어셈블리 코드 lw $s3, 1($0) : ($0)은 상수값 0으로 1 + 0 = 1이며 워드 주소 1을 $s3에가져오라는 것이다. 즉 $s3이 목적지가 된다.
-store 명령어 (sw)
어셈블리 코드 sw $t4, 0x3($0) : ($0)은 상수값 0이므로 16진수의 3과 0을 더해 3이다. 여기서는 $t4가 source, 0x3($0)이 목적지이기 때문에 워드주소 3에 $t4의 값을 쓰라는 것이다.
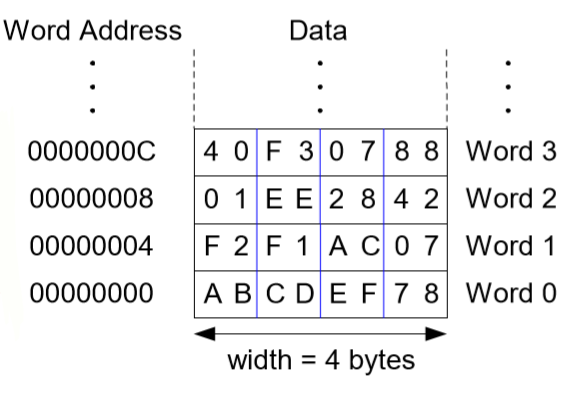
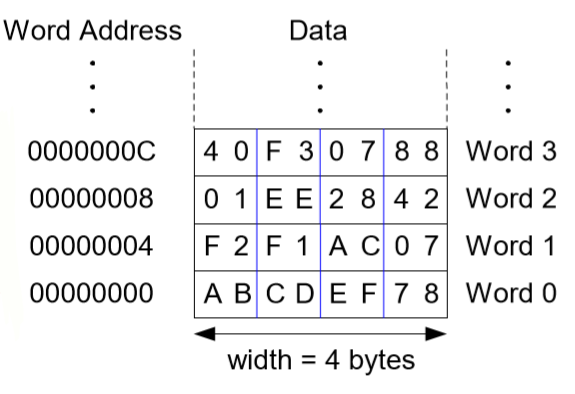
9. 바이트(byte) 주소 메모리
1워드 차이가 주소에서 4씩 차이난다.
-load 명령어 (lw)
항상 가져오는 양은 1word로 정해져있다. 어셈블리 코드 lw $s3, 4($0) : ($0)은 상수값 0으로 4 + 0 = 4이다. 이는 워드 주소 4를 $s3으로 가져오라는 것이다. 즉 $s3이 목적지가 된다.
-store 명령어 (sw)
어셈블리 코드 sw $t7, 12($0) : ($0)은 상수값 0이므로 12와 0을 더해 12이다. 1여기서는 $t7이 source, 12($0)가 목적지이다. 즉 16진수로 12는 C이기 때문에 워드주소 C에 $t7의 값을 쓰라는 것이다.
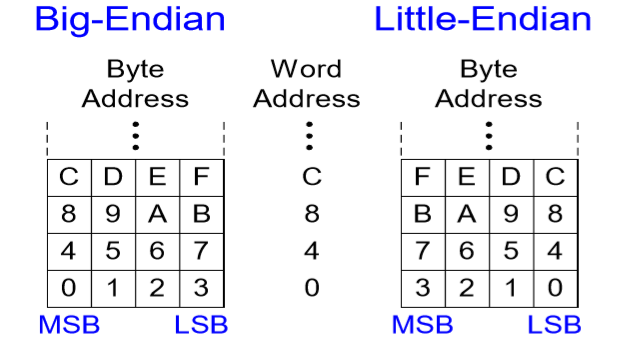
10. 빅-엔디안, 리틀-엔디안
이는 데이터를 읽어오는 방식에 대해 차이가 있다.
MSB는 제일 높은 주소, LSB는 제일 낮은 주소이다. 빅-엔디안은 높은 주소 -> 낮은 주소 순으로, 리틀-엔디안은 낮은 주소 -> 높은 주소 순으로 데이터를 읽어온다.
예제) $t0의 값이 0x23456789라고가정한다. 아래의프로그램이 Big-Endian 시스템과Little-Endian시스템에서 수행한 후에 $s0의값은?
sw $t0, 0($0) lb $s0, 1($0) # 1+0 = 1 즉 1번지의 데이터 값을 $s0에 가져와라.
Big-Endian은 MSB -> LSB 순으로 데이터를 불러오기 때문에 45가 1번지이고, Little-Endian은 LSB -> MSB 순으로 데이터를 불러오기 때문에 67가 1번지이다.
11. 설계 원칙 4
좋은 설계는 좋은 절충안을 요구함
-다중 명령어 형태는 융통성 제공 (1) add, sub: 3개의 레지스터 피연산자 사용 (2) lw, sw: 2개의 레지스터 피연산자와 상수 사용 :적은 수의 명령어 형태를 유지함
12. 기계어
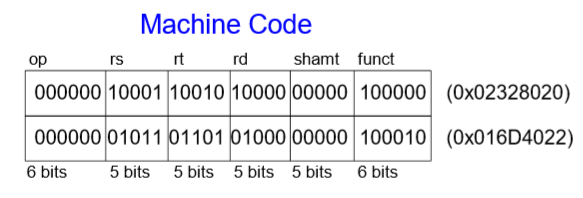
기계어는 32비트 명령어로, 명령어들을 이진 표현한다. 즉 0과 1로만 나타낸다. 명령어 형태로 R-Type, I-Type, J-Type이 있다.
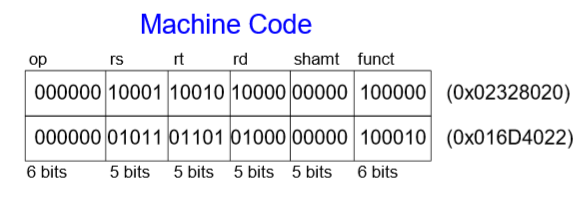
12-1. R-Type
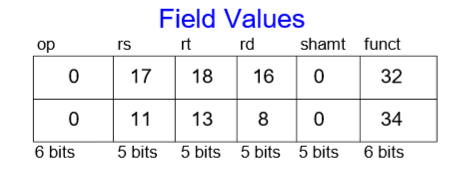
레지스터의 R을 사용한 R-Type은 3개의 레지스터 피연산자(오퍼랜드)를 갖는다. rs, rt는 source 레지스터이며, rd는 destination 레지스터이다. 다른 필드는 op 즉 operation 코드(op코드), funct(function), shamt(shift 명령어에서 사용되는 shift 양)이 있다. R-Type명령어에서는 op코드 값이 모두 0으로 무슨 타입인지 모를 때도 op값을 보고 알 수 있다. shamt는 예로 곱셈, 나눗셈에서 사용되며, funct는 op가 모두 0이기 때문에 명령어를 분류하기 위해 사용한다.
예시)
어셈블리 코드를 먼저 10진수의 R-Type으로 바꾸면
이렇게 된다. R-Type이기 때문에 op코드가 0, rs와 rt는 source, rd는 destination이다. 여기서는 곱셈과 나눗셈이 없으므로 둘 다 0이고 funct는 add는 32, sub은 34로 나타낸다. 이를 기계어 즉 2진수로 바꾸면
결론적으로 이런 값을 얻는다.
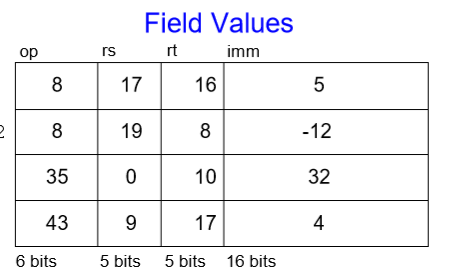
12-2. I-Type
즉시값(Immediate) 타입으로 3개의 피연산자(오퍼랜드)를 가진다. rs, rt는 레지스터 피연산자이며 imm은 16비트의 즉시값이다. 다른 필드로는 op코드가 있다. R-Type과는 달리 funct가 존재하지 않는 이유는 op코드가 이미 개별적인 값을 갖기 때문이다. 여기서 중요한 점은 imm이 10진수의 상수값을 가지는 것이다.
예시)
addi에서 i는 즉시값 타입을 나타내고 있다. 여기서 rt가 목적지, rs와 imm이 source이다. 이를 I-Type으로 나타내면
addi $s0, $s1, 5에서 $s0은 rt로, $s1은 rs로 상수 5는 imm값으로 들어간다. 또한 더하는 명령어의 op코드 값인 8이 op자리에 들어간다. lw $t2, 32($0)에서 처럼 피연산자가 하나, imm값이 하나인 경우에는 피연산자가 rt값에 들어간다. 이를 기계어 코드로 바꾸면
결론적으로 이런 값을 얻는다.
12-3. J-Type
Jump타입으로 1개의 피연산자(오퍼랜드) addr를 가진다. 이는 주소 피연산자이다. 다른 필드로는 op코드가 있다. 분기 명령어 때 사용되는 명령어 형식이다.
addr은 어디로 갈 지의 데이터가 들어있다.
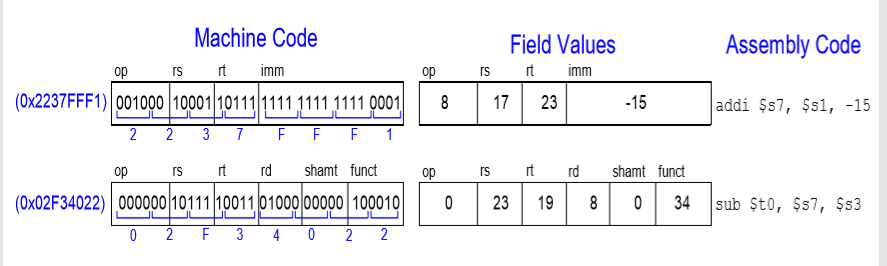
13. 기계어 코드 해석
순서 (1) opcode 분석 (2) opcode가 0이면 R-Type으로 funct비트를 통해서 명령어 기능 분석 (3) opcode가 0이 아니면, I-Type 또는 J-type 명령어
예시)
먼저 0x2237FFF1은 기계어 코드를 4비트씩 쪼개 16진수로 만든 것이다. 또한 op코드가 0이 아니고 imm이 있는 것을 보면 I-Type인 것을 알 수 있다. 0x02F34022도 기계어 코드를 4비트씩 쪼개 16진수로 만든 것이며 op코드가 0이므로 R-Type인 것을 알 수 있다.
14. 조건부 분기 (beq)
먼저 i가 붙은 것을 봐서 I-Type이다. 또한 첫 번째가 목적지임을 생각하고 코드를 분석하면 $s0 = 0 + 4 = 4 $s1 = 0 + 1 = 1 $s1 = 1 << 2 = 4 이다. 여기서 sll 은 시프트 연산으로 예를들어 0001을 왼쪽으로 2 시프트 하면 0100이 되기에 4가 된다. 이후 나오는 beq에서는 $s0과 $s1이 같으면 target으로 가라는 명령어다. 현재 $s0과 $s1은 4로 같기 때문에 target으로 바로 분기한다. 따라서 beq후에 나오는 addi와 sub명령어는 수행하지 않는다. target에서의 코드는 $s1 = 4 + 4 = 8 이다.
15. 조건부 분기 (bne)
bne는 $s0과 $s1이 같지 않을 경우 분기하는데 여기서는 같기 때문에 분기 하지 않고 다음 명령어를 수행한다.
16. 무조건 분기 (j)
무조건 분기의 경우 조건을 따지지않고 분기하기 때문에 목적지 target만 있다. j를 만나면 바로 분기한다. 따라서 sra, addi, sub의 명령어를 수행하지 않는다.
17. 무조건 분기 (jr)
jr은 레지스터를 가지는데 그 레지스터의 데이터를 주소로 판단한다. 즉 $s0으로 무조건 분기하라는 것으로 현재 $s0은 0x2010으로 lw명령어 주소이기 때문에 그곳으로 분기한다. 따라서 사이에 있는 addi와 sra명령어를 수행하지 않는다.
18. if문
if문의 조건은 i와 j가 같으면인데 mips에서는 bne 즉 i와 j가 같지 않으면을 쓴다. 그 이유는 if조건이 같지 않으면 수행을 하지 않아야 하기 때문이다. bne에서 조건이 같지 않으면 add를 수행하면 안되기 때문에 L1으로 분기하는 것이다.
19. if/else문
그냥 if문과는 달리 j done이 추가된 것을 볼 수 있다. if문의 조건이 아니면 else문을 실행해야 하기 때문에 mips에서 bne(조건이 다르면) L1으로 분기하라는 것이 있으며 마만약 조건이 같으면 분기 하지 않고 add를 수행한다. 이후 else문은 수행을 하면 안되므로 j를 사용해 done으로 무조건 분기한다.
20. while루프
while문에서 pow가 128이 아닐동안 수행하는 것이기 때문에 128이 되면 while문을 돌면 안된다. 따라서 mips에서 while문이 beq인 이유가 pow가 128이면 돌지 않고 분기해야하기 때문이다. 또한 while문의 마지막에 j가 있는 이유는 계속해서 돌아야하기 때문에 while로 다시 분기를 하는 것이다.
21. for루프
for문에서 i가 10이 아닐 동안 돌아야하기 때문에 i가 10이 되면 돌지 않아야 한다. 따라서 mips에서 i가 10일 경우 분기하도록 beq $s0, $t0, done이 되어 있다. 또한 계속 돌기위해 for문 마지막에 다시 for문으로 분기하는 j 명령어가 있다.
22. Less Than 비교
먼저 볼 것은 loop에 있는 slt명령어이다. 이는 Set on less than의 약자로 slt $t1, $s0, $t0 dms 만약 $s0 < $t0이면 $t1에 1을 넣고 아니면 0을 넣으라는 것이다. 즉 slt a, b, c가 있으면 b와 c를 비교해 a값을 정하는 것이다. 또한 loop의 beq는 break코드로 이해하면 된다. slt에서 i가 101보다 크거나 같으면 0을 넣기 때문에 beq에서 $t1이 0이면 분기하면 된다.
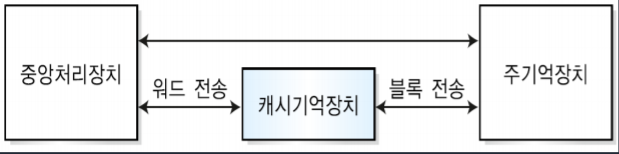
cpu안에 있는 것이 아니며 주기억장치와 분리되어 있다. cpu안에 있는 것은 레지스터이다.
2. 특징
자주 사용되는 명령어들을 저장하고 있다가 cpu가 필요할 때 빠르게 제공하며 데이터를 저장하고 인출하는 속도가 주기억장치보다 빠르다. 속도가 주기억장치보다 빠르고 cpu보다 느리기 때문에 둘의 속도 차이를 줄여주는 고속완충기억장치이며 용량이 작고 비싸지만 빠르다는 장점이 있다.
3. 캐시 기억장치가 없는 시스템
-동작원리
1단계: CPU가 명령어와 데이터를 인출하기 위해서 주기억장치에 접근한다.
2단계: 주기억장치에서 명령어나 필요한 정보를 획득하여 CPU내의 명령어 레지스터 등에 저장한다.
-특징: 주기억장치에 매번 접근해야하기 때문에 속도가 너무 느리다는 단점이 있다.
4. 캐시 기억장치가 있는 시스템
-동작원리
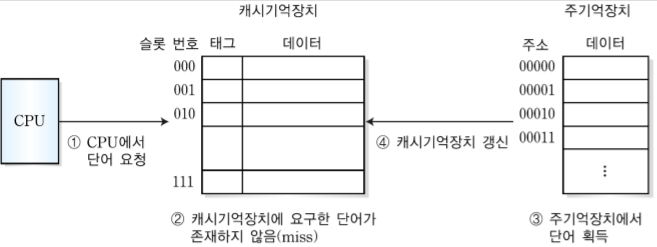
CPU가 명령어 또는 데이터를 인출하기 위해 주기억장치보다 캐시기억장치를 먼저 조사한다. 만약 캐시기억장치에서 그 명령어 또는 데이터가 있으면 적중(hit)이라고 하고, 없으면 실패(miss)라고 한다.
적중일 경우 주기억장치를 방문하지 않고 캐시기억장치에서 얻어진 정보를 CPU로 전송한다.
실패일 경우 주기억장치 들려서 캐시기억장치에 넣고 캐시에서 가져온다. 이때, 굳이 캐시에 넣고 다시 캐시에서 꺼내오는 이유는 나중에 다시 쓸 수도 있기 때문이다.
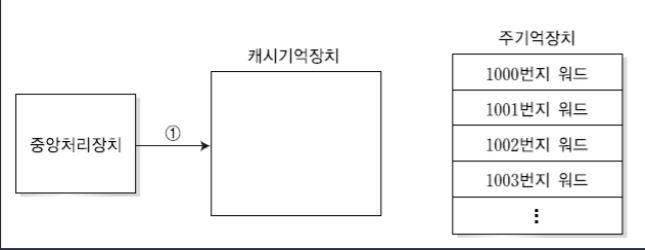
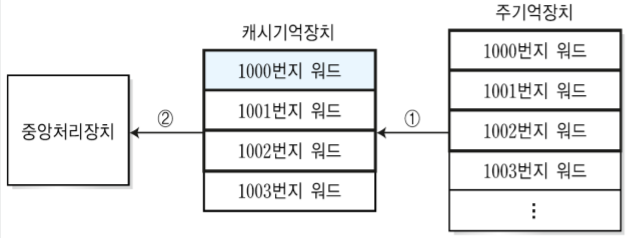
4-1. miss
CPU가 1000번지의 워드가 필요한 경우, 지금 상황에서는 캐시기억장치가 빈 상태이기 때문에 실패상태가 된다.
실패상태일 경우 1000번지가 필요하니까 1000번지를 가져오는데 1001, 1002, 1003도 나중에 CPU가 사용할 것이라고 유추되면 가져온다.
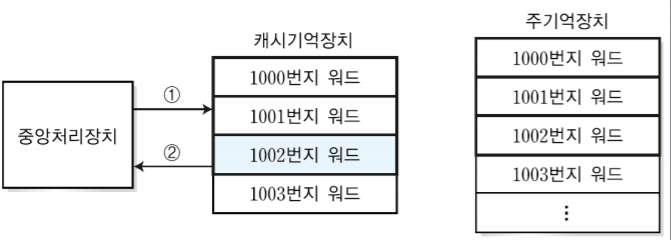
4-2. hit
CPU가 1002번지의 워드가 필요한 경우
캐시기억장치에 먼저 접근해서 1002번지 워드가 있는지 검사하는데 지금 상황의 경우 캐시기억장치에 1002번 워드가 있기 때문에 주기억장치에 접근하지 않고 캐시기억장치에서 바로 가져온다.
5. 캐시 기억장치의 적중률
적중률: 캐시 기억장치의 성능을 나타내는 척도
적중률이 높을수록 데이터 액세스 속도가 향상된다.
적중률은 0에서 1사이의 값으로 나타낼 수 있으며 예를들어 10번 캐시기억장치에 접근했을 때 3번 hit을 했다면 3/10으로 적중률은 0.3(30%)이다.
이를 기반으로 주기억장치와 캐시기억장치에서 데이터를 인출하는데 소요되는 평균 기억장치 접근시간을 알 수 있다.
Taverage
주기억장치와 캐시기억장치에서 데이터를 인출하는데 소요되는 평균 기억장치 접근 시간
Tmain
주기억장치 접근시간
Tcache
캐시기억장치 접근 시간
Hhit_ratio
적중률
결론적으로 Taverage = Hhit_ratio * Tcache + (1-Hhit_ratio) * Tmain으로 구할 수 있다.
예제) Tcache = 50ns, Tmain = 400ns일 때, 적중률을 증가시키면서 기억장치 접근시간 계산을 하면
적중률 70%
Taverage = 0.7 * 50ns + 0.3 * 400ns = 155ns
적중률 80%
Taverage = 0.8 * 50ns + 0.2 * 400ns = 120ns
적중률 90%
Taverage = 0.9 * 50ns + 0.1 * 400ns = 85ns
적중률 95%
Taverage = 0.95 * 50ns + 0.05 * 400ns = 67.5ns
적중률 99%
Taverage = 0.99 * 50ns + 0.01 * 400ns = 53.5ns
여기서 알 수 있는 점은 먼저 Tcache, Tmain 값을 봤을 때 캐시 접근이 훨씬 적은 시간이 걸린다는 것과, 적중률이 커지면서 주기억장치에 접근하는 횟수가 적어지기 때문에 결론적인 기억장치 접근시간이 훨씬 줄어드는 것이다.
6. 캐시 기억장치의 설계
주기억장치와 캐시기억장치 간의 정보 공유
워드는 CPU가 한 번에 처리할 수 있는 데이터 단위이고 이 워드들이 모이면 블록이된다.
*캐시기억장치 설계시 고려해야할 요소
캐시기억장치의 크기(size)
인출방식(fetch algorithm)
사상함수(mapping function)
교체 알고리즘(replacement algorithm)
쓰기 정책(write policy)
블록 크기(block size)
캐시기억장치의 수(number of caches)
6-1. 캐시 기억장치의 크기
-캐시기억장치의 크기가 클수록 확보할 수 있는 요량이 커지기 때문에 적중률은 높아지지만 즉 hit하는 횟수가 많아지지만 캐시 내용을 모두 확인하는데 시간이 많이 걸리기 때문에 평균 접근 시간과 비용이 증가한다.
-적중률을 향상시키고 평균 접근시간에 대한 저하를 막는 최적의 크기 결정이 필요한데 1K ~ 128K 단어(word)가 최적이라고 한다.
6-2. 인출 방식
인출방식이란 주기억장치에서 캐시기억장치로 명령어나 데이터 블록을 인출해 오는 방식이다.
요구인출(Demand Fetch) 방식
CPU가 현재 필요한 정보만을 주기억장치에서 블록 단위로 인출해 오는 방식
선인출(Prefetch) 방식
CPU가 현재 필요한 정보 외에도 앞으로 필요할 것이 예측되는 정보도 미리 인출하여 캐시기억장치에 저장하는 방식이다. 예를 들어 어떠한 데이터를 인출할 때 그 정보와 이웃한 위치에 있는 정보들을 함께 인출하여 캐시에 적재한다. 이는 정보를 예측하기위해 학습시켜야하기 때문에 요구인출보다 어려운 방식이다.
6-3. 사상함수
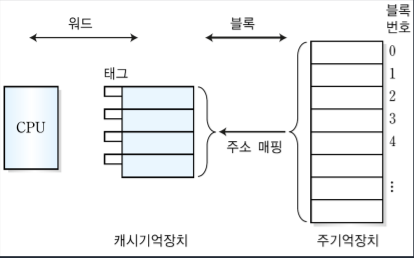
사상이란 Mapping이라고 하며 주기억장치와 캐시기억장치 사이에서 정보를 옮기는 것을 말한다.
먼저 주기억장치의 구조를 보면 하나의 주소번지에 저장되는 데이터의 단위를 단어(word)라고 하며 단어가 모이면 블록이된다. 캐시기억장치의 구조를 보면 슬롯과 태그가 있는데 슬롯은 데이터 블록이 저장되는 장소이고, 태그는 슬롯에 적재된 데이터 블록을 구분해주는 정보이다.
캐시기억장치의 사상방법에는 직접사상, 연관사상, 집합 연관 사상으로 총 3가지가 있다.
6-3-1. 직접 사상(direct mapping)
특징: 캐시기억장치로부터 데이터 블록 인출을 위해 데이터 블록의 슬롯번호에 해당하는 슬롯만 검색하면 된다.
장점: 사상 과정이 간단함
단점: 동일 슬롯 번호를 갖지만 태그가 다른 데이터 블록들에 대한 반복적인 접근은 적중률을 떨어뜨림
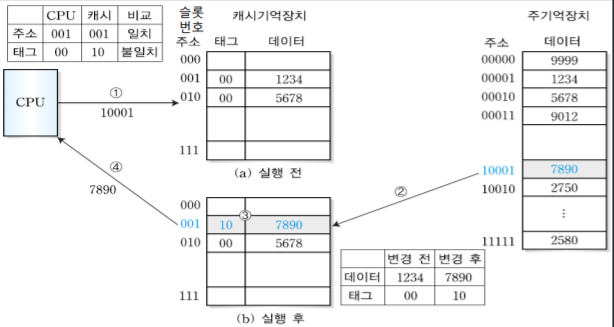
예제)
1
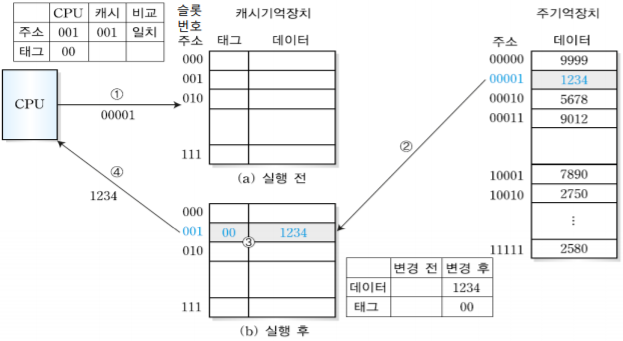
CPU가 00001번지의 블록을 필요로 하는 경우 실행 전 캐시기억장치는 비어있기 때문에 먼저 주기억장치의 주소를 2개, 3개로 잘라서 앞에 00은 태그로, 뒤에 001은 슬롯번호로 가며 데이터는 그대로 데이터로 넣는다.
2
CPU가 10001번지 블록을 필요로하는 경우도 예제 1번과 똑같이 진행된다.
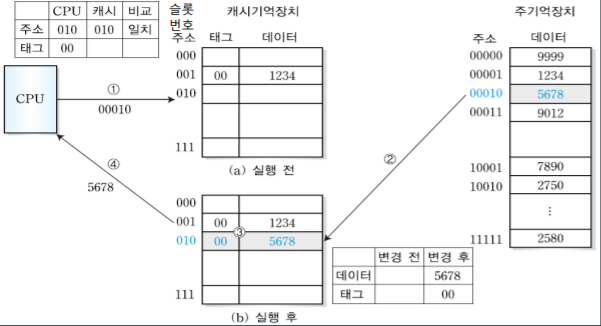
3
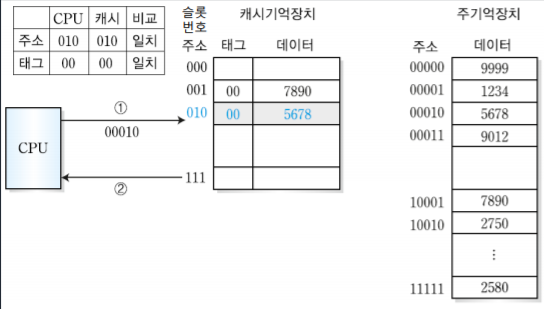
하지만 CPU가 00010번지 블록을 필요로 하는 경우 예제1번과 슬롯번호가 같기 때문에 혼동이 생기며, 태그번호는 다르기 때문에 다시 주기억장치에서 새로 데이터를 가져온다.
4
다음으로 CPU가 00010번지의 블록을 필요로하는 경우 아까 예제 2에서 캐시 기억장치에 넣어놨으니 주기억장치에 접근하지 않고 캐시기억장치에서 바로 데이터를 가져온다.
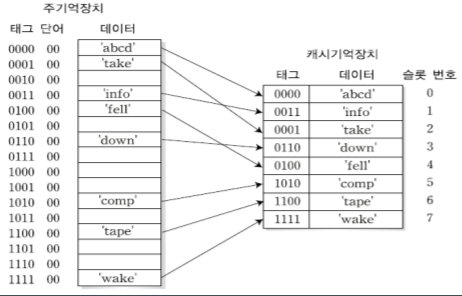
6-3-2. 연관 사상(associative mapping)
캐시슬롯번호에 상관없이 주기억장치의 데이터블록을 캐시기억장치의 임의의 위치에 저장한다.
특징: 캐시기억장치로부터 데이터 블록 인출을 위해서 모든 슬롯에 대한 검색이 필요하다.
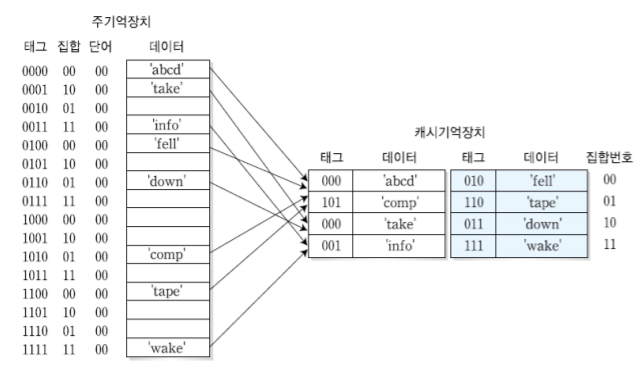
6-3-4. 집합 연관 사상(set-associative mapping)
직접 사상과 연관 사상 방식을 조합한 방식으로 아주 중요하다!
캐시는 v개의 집합들로 나뉘며, 각 집합들은 k개의 슬롯으로 구성된다.
직접 사상 방식에 의해 v개의 집합들 중 하나의 집합을 선택하고, 연관 사상 방식에 의해 선택한 집합 내의 k개의 슬롯 중에 하나의 슬롯을 선택한다.
집합은 무작위로 설정되며 여기서 하나의 집합에는 2개의 데이터 즉 2개의 태그가 있다.
6-4. 교체 알고리즘
캐시기억장치의 모든 슬롯이 데이터로 채워져있는 상태 즉 full인 상태에서 실패일 때, 주기억장치에서 새로운 데이터 블록을 가져와서 캐시기억장치에 넣어야하는데 이 때 캐시에 있던 데이터 중 무엇을 제거할지 결정하는 방식이다.
직접사상은 교체 알고리즘이 필요지만 연관, 집합 연관 사상에는 교체 알고리즘이 필요하다.
종류
LRU(Least Recently Used)
최소 최근 사용 알고리즘
LFU(Least Frequently Used)
최소 사용 빈도 알고리즘
FIFO(First in First out)
선입력 선출력 알고리즘
Random
랜덤
6-5. 쓰기 정책
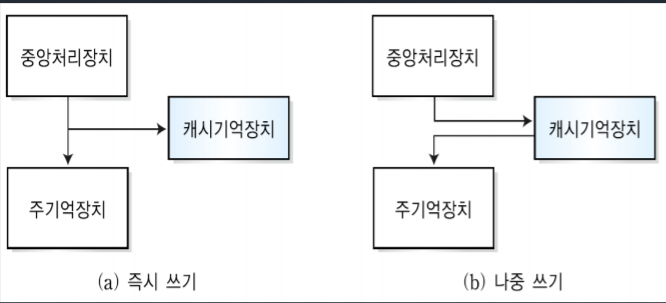
-즉시쓰기(Write-though) 방식
CPU에서 생성되는 데이터 블록을 캐시기억장치와 주기억장치에 동시에 기록한다. 이는 데이터의 일관성을 쉽게 보장할 수 있지만 매번 쓰기 동작이 발생할 때바다 캐시기억장치와 주기억장치간 접근이 빈번하게 일어나고 쓰기시간이 길어지게 된다는 단점이 있다.
-나중쓰기(Write-back) 방식
캐시기억장치에 기록한 후, 기록된 블록에 대한 교체가 일어날 때 주기억장치에 기록한다. 이는 주기억장치에 기록하는 동작을 최소화 할 수 있지만 중간에 데이터의 손실이나 변조의 위험성이 있어 캐시기억장치와 주기억장치 간에 데이터 불일치가 발생할 수도 있다.
6-6. 블록 크기
블록크기가 클수록 한 번에 많은 정보를 읽어올 수 있지만 블록 인출 시간이 길어지게 된다. 블록이 커질수록 캐시기억장치에 적재할 수 있는 블록의 수가 감소하기 때문에 블록이 더 빈번히 교체과 된다. 그래서 일반적으로 4 ~ 8 단어가 적당하다.