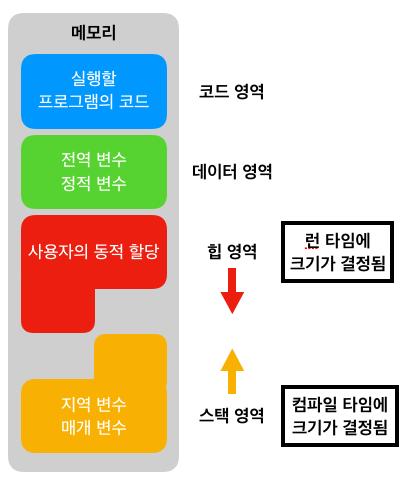
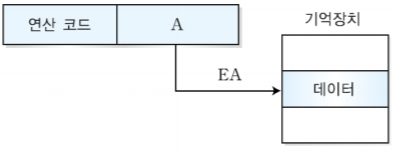
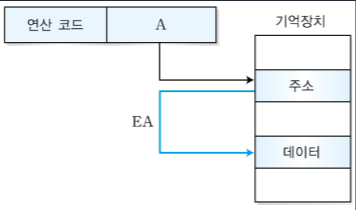
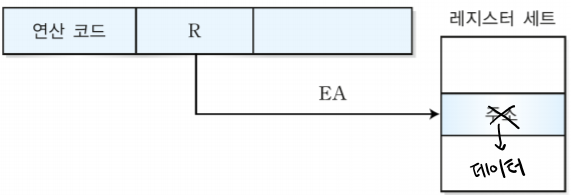
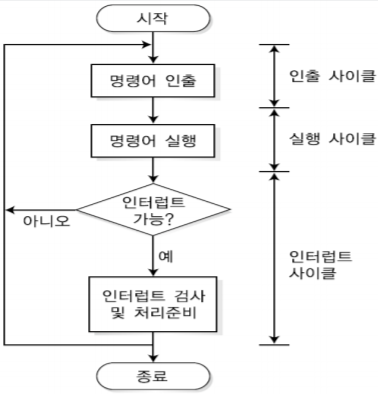
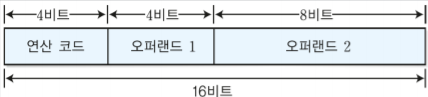
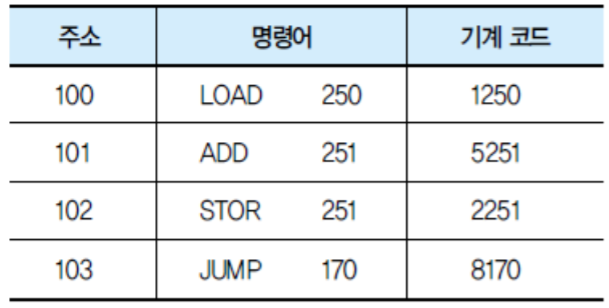
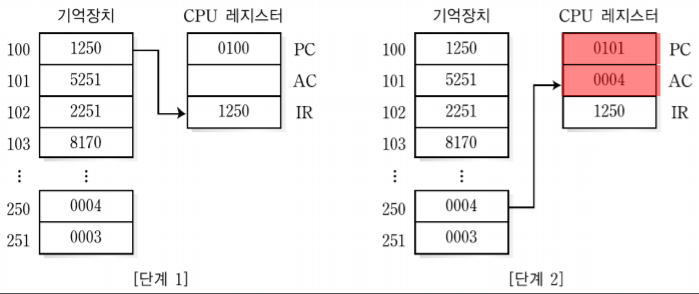
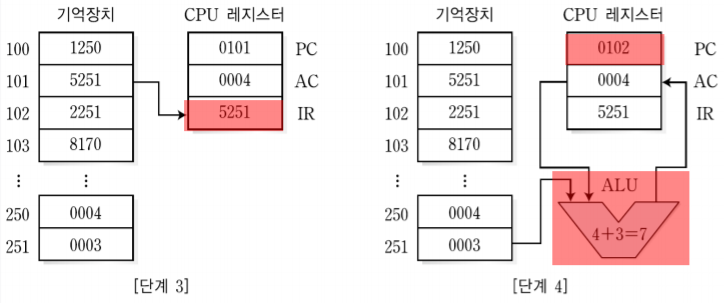
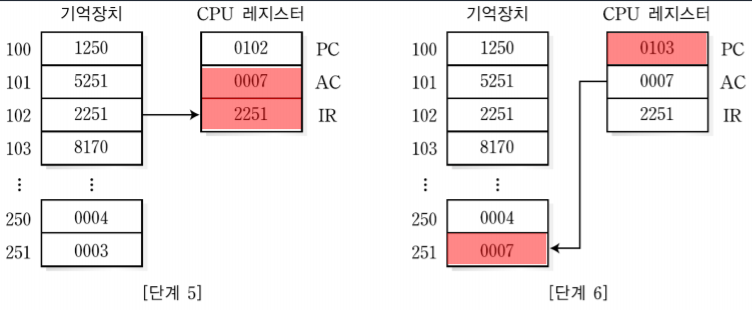
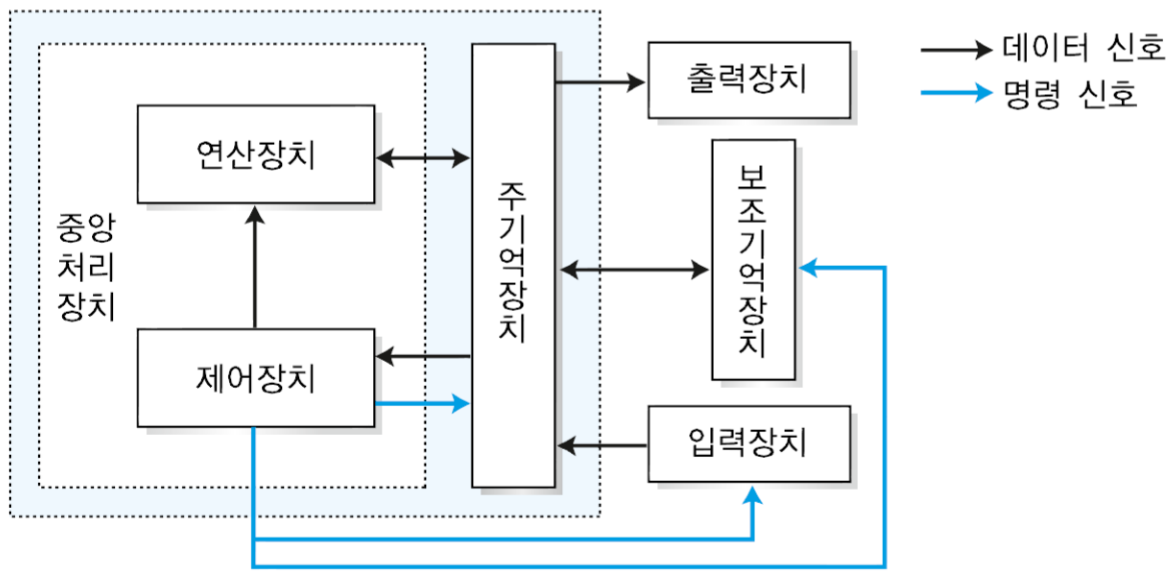
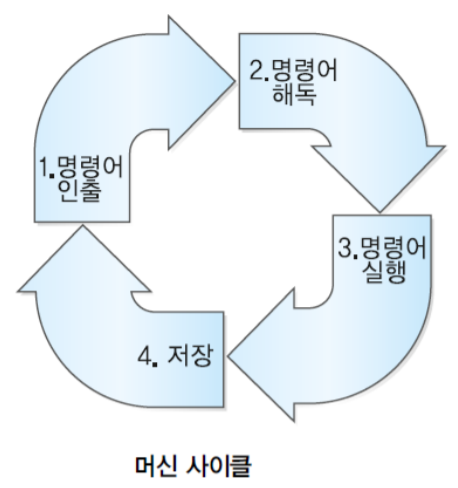
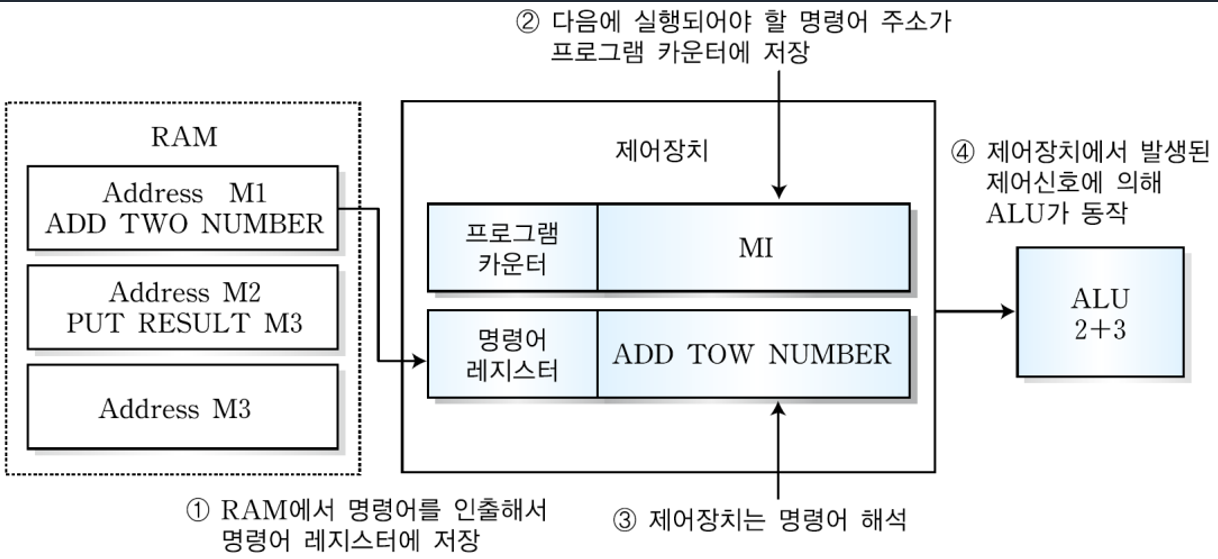
1. 분기 명령어
분기한다: 연속적으로 가지않고 다른 곳으로 간다.
1-1. 분기의 형태
| BRZ(branch if zero) A | 조건 코드가 0이면 A번지로 분기하라는 명령어 |
| BR A | 무조건 A번지로 분기하라는 명령어 |
| BRE(branch if equal) R1, R2, A | 레지스터 R1과 R2의 내용이 같다면 A번지로 분기하라는 명령어 |
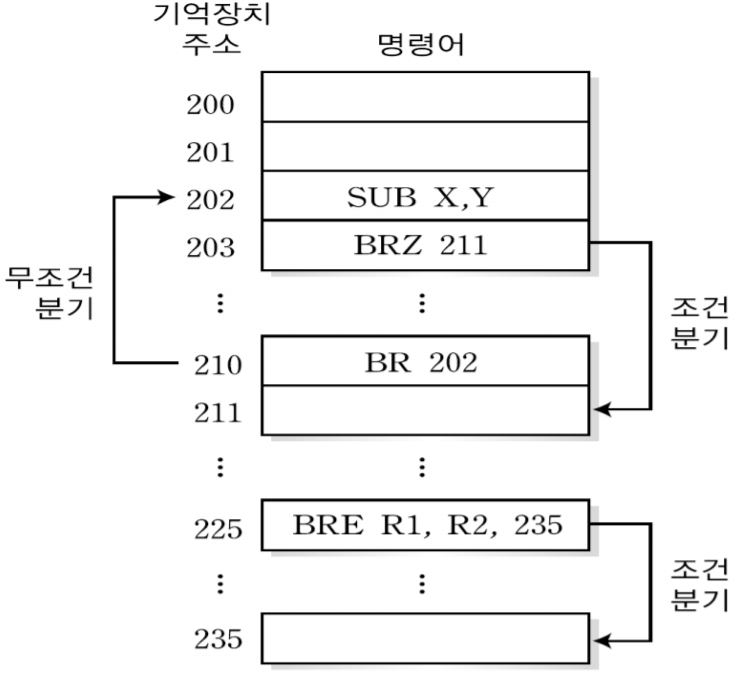
202번지에 있는 SUB X, Y는 X에서 Y를 빼라는 명령어이다. 뺀 값이 0이 아니라면 그대로 가다가 210번지에서 BR 명령어를 만난 후 무조건 202번지로 분기할 것이다. 하지만 뺀 값이 0이라면 203번지에 있는 BRZ 명령어를 만났을 때 조건코드가 0이기 때문에 211번지로 분기한다. 이후 225번지의 BRE 명령어를 만나 레지스터 R1과 R2 내용이 같은지 비교하고, 같다면 235번지로 분기하고 다르다면 226번지로 갈 것이다.
2. 서브루틴
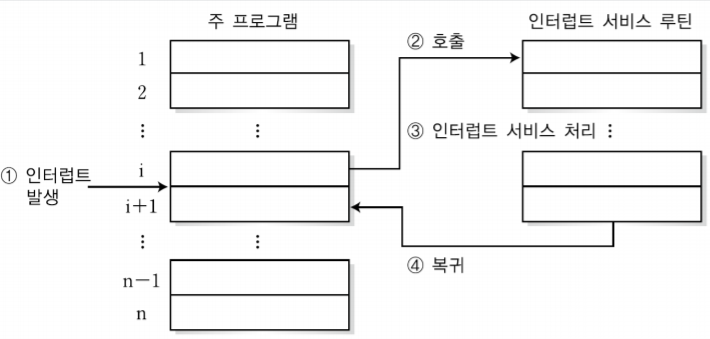
서브루틴은 한 블록으로 구성된 명령어 실행 중에 또 다른 블록으로 구성된 명령어를 삽입하여 실행하는 형태로 호출(CALL)과 복귀 명령어(RET)가 함께 사용된다.
CALL 명령어는 함수를 호출하는 명령어로 돌아와야할 주소를 스택에 저장하고, PC에는 호출될 서브 루틴의 시작 주소를 저장한 후 분기한다. 여기서 스택에 어디로 돌아갈지에 대한 데이터를 넣는 것을 push라고 한다.
RET 명령어는 분기하기 전 프로그램으로 되돌아가는 명령어로 스택에 저장되어있던 주소값을 PC에 넣어 CALL명령어 바로 다음 주소로 되돌아 간다. 여기서 스택에 저장되어있던 주소값을 가지고 오는 것을 pop이라고 한다.
여기서 짚고 갈 것은 push는 어떤 데이터를 넣을지 데이터가 추가적으로 필요하다. 돌아갈 주소가 추가적인 데이터라고 이해하면 된다. 하지만 pop은 추가적인 데이터가 필요없다. 스택은 후입선출구조이기 때문에 무조건 맨 위의 데이터를 가져오기 때문이다.
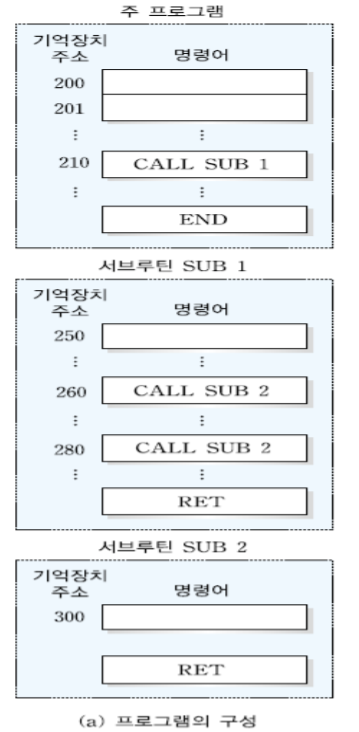
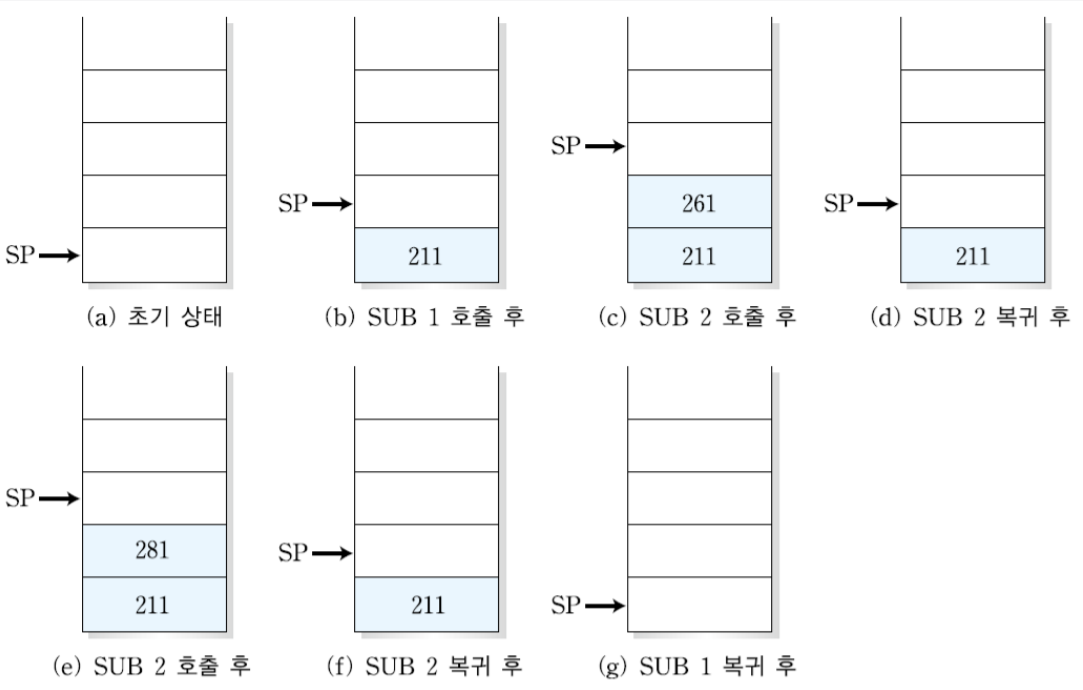
210번지에서 서브루틴 SUB1을 호출하면 현재 주소 + 1 = 211을 스택에 넣는다. 돌아왔을 때 210번지의 CALL SUB1을 만나면 무한대로 호출만 하기 때문이다. 그리고 SUB1의 시작주소 즉 250번지의 값을 pc에 넣고 250번지로 분기한다.
이후 260번지에서 서브루틴 SUB2를 호출했기 때문에 260 + 1 = 261을 스택에 넣고 SUB2의 시작주소인 300번지의 값을 pc에 넣고 300번지로 분기한다.
SUB2를 다 돌고 RET명령어를 만나면 다시 *스택포인터가 가리키는 주소를 pc값에 넣고 돌아온다. 261번지로 돌아와 명령어를 수행하던 도중 다시 280번지에서 SUB2를 호출하면 281을 다음 주소인 281을 스택에 넣고 SUB2의 시작주소인 300번지로 분기한다.
SUB2에서 RET를 만나 SUB1로 와서 RET를 만난 후 최종적으로 주프로그램의 END까지 만나면 프로그램이 종료된다.
*sp는 스택포인터로 스택의 맨 위를 가리킨다. RET 명령을 만나면 pop한 후 sp는 하나 밑으로 간다.
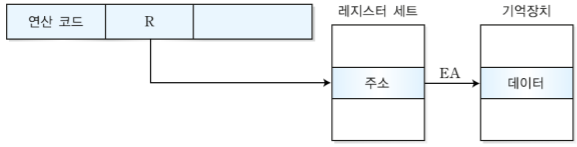
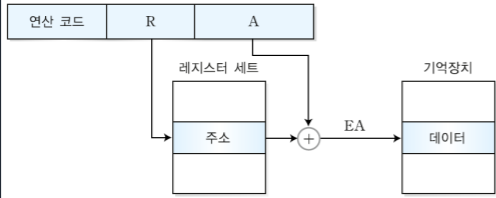
3. 명령어 분류
오퍼랜드에 저장되는 데이터의 형태에는 4가지가 있다.
| 주소 | 주기억장치의 주소나 레지스터의 주소 |
| 수 | 정수, 고정-소수점 수, 부동-소수점 수 |
| 문자 | ASCII 코드 |
| 논리 데이터 | 비트(bit)혹은 플래그(flag) |
오퍼랜드의 수에 따라 다음과 같이 3, 2, 1, 0 주소 방식이 있다.
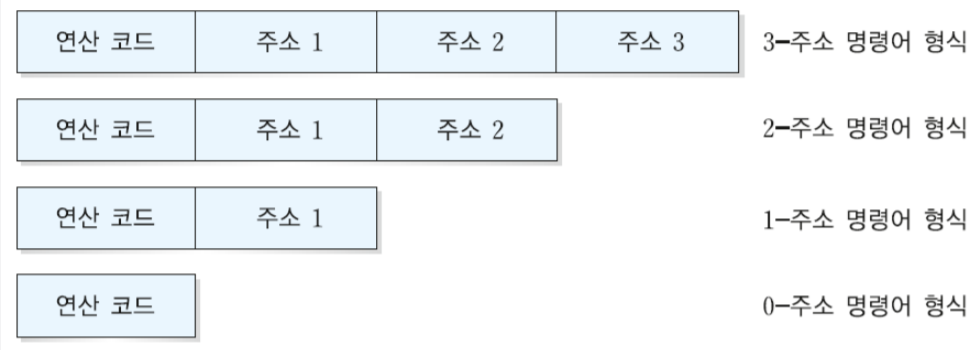
이제 하나씩 자세히 알아보자.
3-1. 0주소 명령어

0주소 명령어는 오퍼랜드 없이 연산코드만 있는 것이다.
모든 연산은 스택의 자료들을 활용하기 때문에 스택머신이라고도 한다.
주소를 사용하지 않아 스택의 내용을 변경하면서 수행하기 때문에 원본 데이터가 없다.
3-2. 1주소 명령어

1주소 명령어는 주소의 형태 오퍼랜드 1개를 가진다.
어셈블리 언어) LOAD X ;AC <- M[X]
*어셈블리어는 ;이 주석이다.
LOAD는 연산코드 X는 기억장치 주소로 X를 가지고 오라는 명령어이다.
M은 메모리를 말하고, []는 포인터같은 역할로 X번지의 데이터를 누산기(AC)에 저장하라는 것이다.
3-3. 2주소 명령어

2주소 명령어는 오퍼랜드 2개를 포함하는 명령어 형식으로, 둘다 주소를 저장한다.
주로 목적지에 다시 값을 넣음으로 목적지에 있던 원본 데이터가 없어진다.
어셈블리 언어) MOV X, Y ;M[X] <- M[Y]
MOV는 이동시키는 명령어로 X가 목적지주소, Y가 소스주소이다. 즉 Y번지의 기억장치 데이터를 X번지의 기억장치로 이동시킨다.
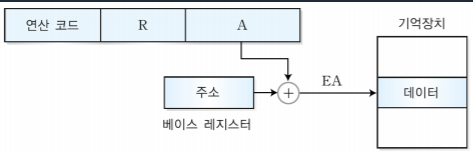
3-4. 3주소 명령어

3주소 명령어는 오퍼랜드 3개를 포함하는 명령어 형식으로, 레지스터 주소들을 저장한다.
원본 자료를 파괴하지 않으며 프로그램 전체의 길이가 짧아지지만 명령어 한 개의 길이가 너무 길어진다는 단점이 있다.
또한 하나의 명령을 수행하기 위해 최소 4번의 기억장소 접근이 필요하여 수행시간이 길어진다.
어셈블리 언어) ADD X, Y, Z ;M[X] <- M[Y] + M[Z]
ADD는 더하라는 명령어로 뒤에서 부터 읽어 앞에 넣는다. X가 목적지 주소, Y가 소스2 주소, Z가 소스1 주소이다. 즉 Y와 Z번지의 데이터를 덧셈해서 X번지에 저장하는 것이다.
*목적지 주소가 있는 오퍼랜드의 위치는 cpu제조사 마다 다를 수 있음!
3-5. 4가지 주소 형식을 사용한 수식 연산 프로그램
X = B * (C + D * E - F / G) 연산 프로그램을 구현후 비교
*사용할 명령어들에 대한 정리
| 명령어 | 동작 |
| ADD | 덧셈 |
| SUB | 뺄셈 |
| MUL | 곱셈 |
| DIV | 나눗셈 |
| MOV | 데이터 이동 |
| LOAD | 기억장치로부터 데이터 적재(데이터 가져옴) |
| STOR | 기억장치로 데이터 저장 |
3-5-1. 0주소 명령어를 사용한 프로그램
0주소는 push랑 pop만쓰고 STOR을 쓰지 않는다.
X = B * (C + D * E - F / G)

0주소 명령어가 실행될 때 스택의 내용을 보자.
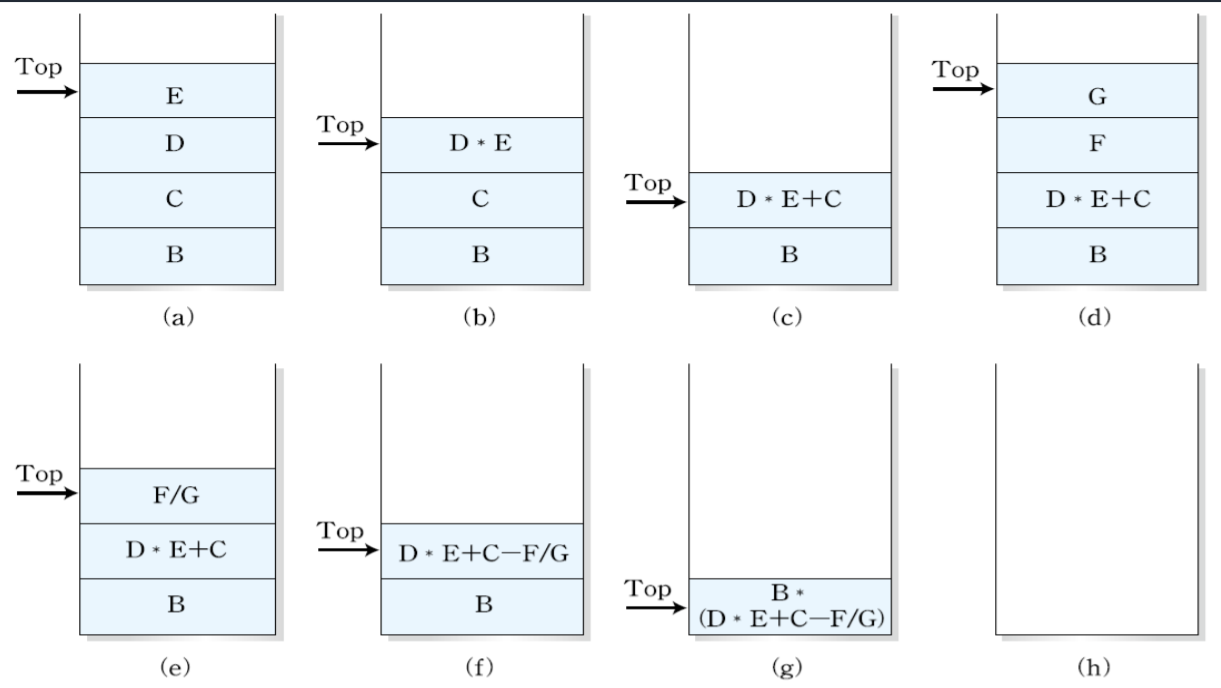
피연산자는 PUSH하고, 연산자를 만나면 연산에 사용할 피연산자를 POP한 후에 연산 결과를 PUSH한다.
여기서 B와 C를 바로 곱하지 않는 것은 괄호가 들어갔기 때문이다. 괄호가 들어오면 플래그 레지스터가 활성화 되어서 여는 괄호가 닫는 괄호를 만날 때까지 수행하지 않는다.
3-5-2. 1주소 명령어를 사용한 프로그램
X = B * (C + D * E - F / G)

여기서 AC는 누산기이고 M[A]는 기억장치 A번지에 저장된 데이터 내용을 가리킨다.
106번지 STOS T에서 STOS는 Store String으로 EDI가 가리키는 주소에 EAX값을 저장한다.
T는 기억장치 내의 임시 저장장소의 주소를 나타낸다.
1주소 명령어는 항상 기준이 누산기이다. 누산기에 있는 값을 연산한 후 다시 누산기에 넣는다.
3-5-3. 2주소 명령어를 사용한 프로그램
X = B * (C + D * E - F / G)

2주소는 명령어 A, B에서 A가 목적지, B가 소스 주소이다.
M[A]는 기억장치 A번지에 저장된 데이터 내용이며 R1, R2는 cpu내의 위치한 레지스터이다.
3-5-4. 3주소 명령어를 사용한 프로그램
X = B * (C + D * E - F / G)

3주소는 명령어 A, B, C에서 A가 목적지, B가 소스1, C가 소스2 주소이다. 여기서 주의해야할 점은 DIV나 SUB같은 명령어처럼 소스의 순서가 바뀌면 아예 값이 바뀌는 경우이다. 꼭 소스1에서 소스2를 연산하도록 해야한다.
*목적지 주소가 있는 오퍼랜드의 위치는 cpu제조사 마다 다를 수 있음!!
3-5-5. 명령어 주소 개수에 따른 장단점
많은 주소를 쓰면 전체적인 명령어 프로그램 길이가 짧아진다. 대신 하나의 명령어 처리 속도가 느려진다. 반면에 주소 개수가 적으면 명령어 인출과 실행 속도가 높아지며 프로그램 길이가 길어진다. 예를 들어 0주소는 가져오는 것, 더하는 것, 넣는 것 모두 따로 있다면 3주소는 가져와서 더하고 넣은 것이 하나의 명령어에 있기 때문이다.
문제
1. 분기의 형태 중 조건 분기를 하는 명령어를 모두 고르시오.
1) BRZ
2) BRT
3) BR
4) BRE
5) BRA
2. 서브루틴은 호출 명령어 ( )와 복귀 명령어 ( )가 함께 사용된다.
3. 현재 pc값이 259에서 260으로 바뀌었다. 이 때 스택에 들어갈 주소(A)와 pc값에 들어갈 주소값(B)을 쓰시오.
4. PUSH F는 몇주소 명령어인지 쓰시오.
( )
5. 프로그램의 코드 일부분을 해석한 것이다. 몇주소 명령어인지 쓰시오.
코드 해석:
AC <- M[F]
AC <- AC / M[G]
M[T] <- AC
AC <- M[D]
( )
답안
1. 1, 4
BRZ는 조건코드가 0이면 분기하라는 명령어이고 BRE는 레지스터의 내용이
같다면 분기하라는 명령어로 둘 다 조건코드가 있기에 조건 분기를 한다.
하지만 BR은 무조건 분기하라는 명령어로 무조건 분기를 하며
BRT와 BRA는 분기 명령어가 아니다.
2. CALL, RET
3. (A)261, (B)300
스택에는 돌아올 주소가 들어가야한다. 현재 260번지이므로 돌아왔을 때는
260 + 1인 261번지로 와야한다.
pc값은 다음으로 갈 주소가 있어야한다. CALL SUB2명령어는 서브루틴
SUB2를 호출하라는 뜻으로 SUB2의 시작주소 300이 들어가야한다.
4. 0주소 명령어
push는 스택 명령어로 스택을 사용하는 0주소 명령어에서 쓰인다.
5. 1주소 명령어
AC는 누산기이다. 연산값을 누산기로 다시 넣는 것을 보아
누산기를 쓰는 1주소 명령어이다.
'Computer Science (CS) > Computer Structure' 카테고리의 다른 글
| [컴퓨터구조 #8] MIPS (0) | 2020.06.11 |
|---|---|
| [컴퓨터구조 #7] 캐시 기억장치 (0) | 2020.06.02 |
| [컴퓨터구조 #5] 메모리구조와 레지스터 (4) | 2020.05.23 |
| [컴퓨터구조 #4] 명령어 실행 기법 (2) | 2020.05.22 |
| [컴퓨터구조 #3] 컴퓨터 프로그래밍 언어 (0) | 2020.04.17 |